유전자 알고리즘
태그 :
- 개념
- <선택, 교배, 돌연변이> 유전자알고리즘(Genetic Algorithm)의 정의 - 자연세계의 진화현상에 기반한 계산 모델 - 유전자알고리즘(GA)는 탐색과 최적화 문제 해결을 위한 알고리즘으로 진화론의 적자생존과 자연선택의 유전학에 근거한 적응 탐색 기법
## Ⅰ. 탐색과 최적화 문제 해결을 위한 알고리즘, 유전자알고리즘의 개요
### 가. 유전자알고리즘(Genetic Algorithm)의 정의
- 자연세계의 진화현상에 기반한 계산 모델
- 유전자알고리즘(GA)는 **탐색과 최적화 문제 해결을 위한 알고리즘**으로 진화론의 적자생존과 자연선택의 유전학에 근거한 **적응 탐색 기법**
### 나. 유전자 알고리즘(진화적 알고리즘)의 중심이론 Darwin이론
| 구성요소 | 설명 |
| -------- | -------- |
| 적응도(fitness) | 개체가 장래의 세대에 영향을 주는 범위를 결정 |
| 생식 오퍼레이타
(reproduction operator)| 개체가 다음세대에 자손을 생성| | 유전자 오퍼레이타
(genetic operator)| 부모의 유전자 정보로부터 자손의 유전자 정보를 결정| - 진화적 연산에 있어서 중심으로 되는 것은 거의 Darwinian이론의 단순화된 메카니즘의 응용이다. 특히 대부분의 응용은 다음 3가지의 기본적인 구성요소를 가짐. ### 다. 생물학과 유전자 알고리즘의 용어비교 |생물학 | 유전자 알고리즘 |
| -------- | -------- |
| 염색체(chromosome)
유전자(gene)
대립 유전자(allele)
유전자좌(locus)
유전형(genotype)
표현형(phenotype)
에피스타시스(epistasis) | 문자열(string)
특성(feature), 형질(character)
특성치 (feature value)
문자열의 위치(string position)
구조체(structure)
파라메터 집합(parameter set)
대체해(alternative solution),
디코드화를 위한 구조체(a decoded structure)
비선형성(nonlinearity)| ## Ⅱ. 유전자 알고리즘의 프로세스 ### 가. 유전자 알고리즘 흐름도 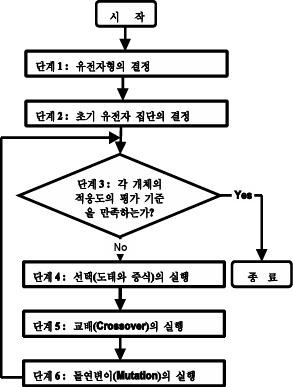 1) 용어설명 |용어 | 설명 |
| -------- | -------- |
| 선택(selection) | 집단 중에서 적응도의 분포에 따라서 다음의 단계로 교배를 행하는 개체의 생존 분포를 결정한다. 적응도의 분포에 기초하고 있기 때문에 적응도가 높은 개체일수록 보다 많은 자손을 남기기 쉽게 된다|
| 교배(crossover) | 2개의 염색체 사이에서 유전자를 바꾸어 넣어 새로운 개체를 발생시킨다|
| 돌연변이(mutation) | 유전자의 어떤 부분의 값을 강제적으로 변화시킨다. |
2) 단계설명
| 용어 | 설명 |
| -------- | -------- |
| 단계 1
유전자형의 결정| - 대상으로 하는 문제로부터 "기호열"이라고 하는 변환을 수행하는 것 | | 단계 2
초기유전자 집단의 결정 | - 결정한 유전자형을 중심으로한 일정범위내에서의 변화를 인정한 복수의 생물개체의 생성처리| | 단계 3
각 개체의 적응도의 평가 | - 여기서는 각 개체의 적응도를 미리 결정한 방법으로 연산 | | 단계 4
선택 | - 단계 3에서 결정한 적응도에 기초하여 다음 단계에서 교배를 수행하는 개체의 생존 분포를 결정
- "도태처리"와 "증식처리" 단계
- 도태처리 : 각 개체의 평가에 기초하여 각 개체마다의 삭제처리
- 증식처리 : 도태처리에 의해 감소한 집단수를 랜덤샘플링에 의해 개체를 증식시켜 집단 수를 증가하는 처리 | | 단계 5
교배처리| - 2개의 염색체 사이에서 유전자를 바꾸어 넣어 새로운 개체를 발생
- 유전자형으로서 정의되어 있는 정보를 개체사이에 바꾸어 넣는 처리| | 단계 6
돌연변이 처리 | - 유전자의 어떤 부분의 값을 강제적으로 변환, 유전자 집단으로서의 다양성 확대
- 유전자형으로서 정의되어 있는 유전자정보의 기호열을 특정의 확률(변이율)로 변화시키는 처리| | 단계 7
반복| - 단계 3으로 되돌아 가고, 각 개체의 적응도를 평가한다| ## Ⅲ. 유전자 알고리즘의 여러가지 선택법 - 선택은 집단 중에서 적응도의 분포에 따라 다음 단계로 교배를 수행하는 개체의 생존 분포를 결정하는 것이다. 기본적인 선택 방법은 다음과 같으며, 이들이 조합되어 사용되는 것도 있다 |**(1) 적응도 비례 방식** |
| -------- |
| 선택 중에서도 가장 기본적인 방식으로, 각 개체의 자손은 그 적응도에 비례한 확률로 선택될 수 있다. 따라서 적응도가 큰 개체일수록 선택되기 쉽고, 다음 단계의 교배에 참가할 수 있는 가능성이 높아진다.|
| **(2) 에리트 보존 방식 (elitism)** |
| -------- |
| 에리트 보존 방식은 개체 중에서 가장 적응도가 높은 개체는 그대로 다음 세대에 남는 방법이다. 어떤 세대에서의 개체는 교배나 돌연변이에 의한 변형을 받지 않고 다음 세대에 전달된다. 그러나 경우에 따라서 원래는 아주 질이 좋지 않은 유전자가 집단 중에 널리 퍼져 버릴 위험성이 있다. 그 때문에 다른 방식, 예를 들면 다음에 설명하는 기대치 방식 등과 조합하여 사용할 수 있다.|
| (3) 기대치 방식 |
| -------- |
| (1)의 적응도 비례 방식은 적응도로 부터 구해진 확률에 기초하는 선택 방식이었다. 이 경우 만일 개체수가 적으면 선택된 개체 분포가 원하는 분포로부터 크게 멀어져 버릴 가능성이 있다. 예를 들면 주사위를 6회 던져 보다도 1부터 6까지의 눈금이 모두 1회씩 나온다는 것은 좀처럼 발생하지 않을 것이다. 기대치 방식에서는 적응도의 분포에 기초하여 각 개체가 선택될 기대치(개수)를 계산한다. 그리고 어떤 개체가 선택될 때에 그 개체의 기대치를 작게하여 가는 것이다. 이렇게 하는 것에 의해 선택된 개체는 선택되기 어렵고, 적응도 비례 방식에서의 확률에 의한 오차를 가능한한 작게 할 수 있다 |
| (4) 순위(Rank) 방식 |
| -------- |
| 순위 방식에서는 미리 순위와 선택할 개체수와의 관계를 결정해 둔다. 그리고 각 개체를 적응도 순으로 나열하고, 선택할 개체를 결정해 가는 것이다. 적응도의 대소관계만이 고려되기 때문에 적응도 그 자체의 값은 무시된다. |
|(5) 토너먼트 방식 |
| -------- |
| 토너먼트 방식은 집단 중에 결정된 수(실제로는 2개인 경우가 많다)의 개체를 무작위로 선택한다. 그들 중에서 가장 적응도가 높은 개체를 선택하는 것으로 이러한 조작을 필요한 횟수만큼 반복한다|
## Ⅳ. 단순유전 알고리즘 및 흐름도
| 알고리즘 | 흐름도 |
| -------- | -------- |
|procedure SGA()
initialize(Population);
evaluate(Population);
while not (terminal condition satisfied) do
MatingPool = reproduce(Population);
MutationPool = crossover(MatingPool);
Population = mutation(MutationPool);
evaluate(Population);
end while
end procedure | 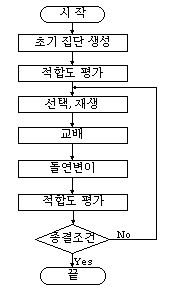 | ## Ⅴ. 유전자 알고리즘의 장단점과 응용분야 ### 가. 유전자알고리즘의 장점과 단점 |구분 | 설명 |
| -------- | -------- |
| 장점| ■ 복수 개의 개체 사이의 상호 협력에 의한 해의 탐색
유전자 알고리즘은 복수의 개체 사이에서 선택이나 교배 등의 유전적 조작에 의해서 상호 협력적으로 해의 탐색을 수행하고 있다.
따라서, 단순한 병렬적 해의 탐색과 비교하여 보다 좋은 해를 발견하기 쉽다.
■ 번거로운 미분 연산 등이 불필요
뉴럴 네트워크, 특히 백프로파게이션 알고리즘 등에서는 평가 함수의 미분값을 필요로 하였다. 유전자 알고리즘에서는 현재 적응도를 분별할 수 있으면 되기 때문에 알고리즘이 단순하고, 평가 함수가 불연속인 경우에도 적용이 가능하다| | 단점 | ■ 대상으로 하는 문제를 유전자 알고리즘으로 해결하기 위한 일반적인 방법이 없다.
특히 문제의 유전자형으로의 표현(코딩)은 설계자의 숙달로 되어 있다.
■ 개체수, 선택 방법이나 교배법의 결정, 돌연변이의 비율 등 파라미터의 수가 많다.| ### 나. 유전자 알고리즘의 응용분야 - 현실의 많은 문제들 중 수학적인 접근으로 풀기 힘든 **비선형성과 불연속성이 강한 문제**에 강점이 있음 - 구체적으로는 소프트웨어 모듈 신뢰성, 스스로 주변의 간섭을 고려하여 전력설정을 할 수 있도록 펨마이크로셀과 펨토셀 사이의 trade-off 관계고려시에도 사용됨 - 과학, 사회과학, 경영학, 공학 등의 분야에서 최적화, 디자인, 예측, 제어, 계획 등을 위해 사용 되고 있음. (참고 : 지능정보시스템 원론 : 정환묵 편저, 21세기사, 1999, Page 354~375)
(reproduction operator)| 개체가 다음세대에 자손을 생성| | 유전자 오퍼레이타
(genetic operator)| 부모의 유전자 정보로부터 자손의 유전자 정보를 결정| - 진화적 연산에 있어서 중심으로 되는 것은 거의 Darwinian이론의 단순화된 메카니즘의 응용이다. 특히 대부분의 응용은 다음 3가지의 기본적인 구성요소를 가짐. ### 다. 생물학과 유전자 알고리즘의 용어비교 |
유전자(gene)
대립 유전자(allele)
유전자좌(locus)
유전형(genotype)
표현형(phenotype)
에피스타시스(epistasis) | 문자열(string)
특성(feature), 형질(character)
특성치 (feature value)
문자열의 위치(string position)
구조체(structure)
파라메터 집합(parameter set)
대체해(alternative solution),
디코드화를 위한 구조체(a decoded structure)
비선형성(nonlinearity)| ## Ⅱ. 유전자 알고리즘의 프로세스 ### 가. 유전자 알고리즘 흐름도  1) 용어설명 |
유전자형의 결정| - 대상으로 하는 문제로부터 "기호열"이라고 하는 변환을 수행하는 것 | | 단계 2
초기유전자 집단의 결정 | - 결정한 유전자형을 중심으로한 일정범위내에서의 변화를 인정한 복수의 생물개체의 생성처리| | 단계 3
각 개체의 적응도의 평가 | - 여기서는 각 개체의 적응도를 미리 결정한 방법으로 연산 | | 단계 4
선택 | - 단계 3에서 결정한 적응도에 기초하여 다음 단계에서 교배를 수행하는 개체의 생존 분포를 결정
- "도태처리"와 "증식처리" 단계
- 도태처리 : 각 개체의 평가에 기초하여 각 개체마다의 삭제처리
- 증식처리 : 도태처리에 의해 감소한 집단수를 랜덤샘플링에 의해 개체를 증식시켜 집단 수를 증가하는 처리 | | 단계 5
교배처리| - 2개의 염색체 사이에서 유전자를 바꾸어 넣어 새로운 개체를 발생
- 유전자형으로서 정의되어 있는 정보를 개체사이에 바꾸어 넣는 처리| | 단계 6
돌연변이 처리 | - 유전자의 어떤 부분의 값을 강제적으로 변환, 유전자 집단으로서의 다양성 확대
- 유전자형으로서 정의되어 있는 유전자정보의 기호열을 특정의 확률(변이율)로 변화시키는 처리| | 단계 7
반복| - 단계 3으로 되돌아 가고, 각 개체의 적응도를 평가한다| ## Ⅲ. 유전자 알고리즘의 여러가지 선택법 - 선택은 집단 중에서 적응도의 분포에 따라 다음 단계로 교배를 수행하는 개체의 생존 분포를 결정하는 것이다. 기본적인 선택 방법은 다음과 같으며, 이들이 조합되어 사용되는 것도 있다 |
initialize(Population);
evaluate(Population);
while not (terminal condition satisfied) do
MatingPool = reproduce(Population);
MutationPool = crossover(MatingPool);
Population = mutation(MutationPool);
evaluate(Population);
end while
end procedure |  | ## Ⅴ. 유전자 알고리즘의 장단점과 응용분야 ### 가. 유전자알고리즘의 장점과 단점 |
유전자 알고리즘은 복수의 개체 사이에서 선택이나 교배 등의 유전적 조작에 의해서 상호 협력적으로 해의 탐색을 수행하고 있다.
따라서, 단순한 병렬적 해의 탐색과 비교하여 보다 좋은 해를 발견하기 쉽다.
■ 번거로운 미분 연산 등이 불필요
뉴럴 네트워크, 특히 백프로파게이션 알고리즘 등에서는 평가 함수의 미분값을 필요로 하였다. 유전자 알고리즘에서는 현재 적응도를 분별할 수 있으면 되기 때문에 알고리즘이 단순하고, 평가 함수가 불연속인 경우에도 적용이 가능하다| | 단점 | ■ 대상으로 하는 문제를 유전자 알고리즘으로 해결하기 위한 일반적인 방법이 없다.
특히 문제의 유전자형으로의 표현(코딩)은 설계자의 숙달로 되어 있다.
■ 개체수, 선택 방법이나 교배법의 결정, 돌연변이의 비율 등 파라미터의 수가 많다.| ### 나. 유전자 알고리즘의 응용분야 - 현실의 많은 문제들 중 수학적인 접근으로 풀기 힘든 **비선형성과 불연속성이 강한 문제**에 강점이 있음 - 구체적으로는 소프트웨어 모듈 신뢰성, 스스로 주변의 간섭을 고려하여 전력설정을 할 수 있도록 펨마이크로셀과 펨토셀 사이의 trade-off 관계고려시에도 사용됨 - 과학, 사회과학, 경영학, 공학 등의 분야에서 최적화, 디자인, 예측, 제어, 계획 등을 위해 사용 되고 있음. (참고 : 지능정보시스템 원론 : 정환묵 편저, 21세기사, 1999, Page 354~375)