앙상블학습(Ensemble learning)
태그 :
- 개념
- Bagging, boosting, 랜덤포레스트, voting 앙상블 학습은 기계 학습의 분류 방법을 통해 여러 개의 분류기(Classifier)를 생성하고 그것들의 예측을 결합함으로써 새로운 가설(Hypothesis)을 학습하는 방법
## Ⅰ. Combining multiple model, 앙상블학습의 개념
### 가. 앙상블학습 개념
- 앙상블 학습은 기계 학습의 분류 방법을 통해 여러 개의 분류기(Classifier)를 생성하고 그것들의 예측을 결합함으로써 새로운 가설(Hypothesis)을 학습하는 방법
- 간단한 알고리즘으로 학습을 수행하되, 복수 개의 학습 결과를 결합함으로써 결과적으로 보다 좋은 성능을 내기 위한 학습 기법
### 나. 앙상블학습 특징
| 특징 | 다수결 |
| -------- | -------- |
| 다수결 이용 | - 다수의 방법을 사용하여 나온 결과를 다수결에 따라 결정하는 방법 |
| 낮은 정확도에서 효과적 | - 앙상블에 사용할 각 방법이 정확도가 낮은 경우에만 효과 있음 |
| 활용기법 | - 의사결정트리 |
## Ⅱ. 앙상블학습 개념도
### 가. 앙상블학습 개념도
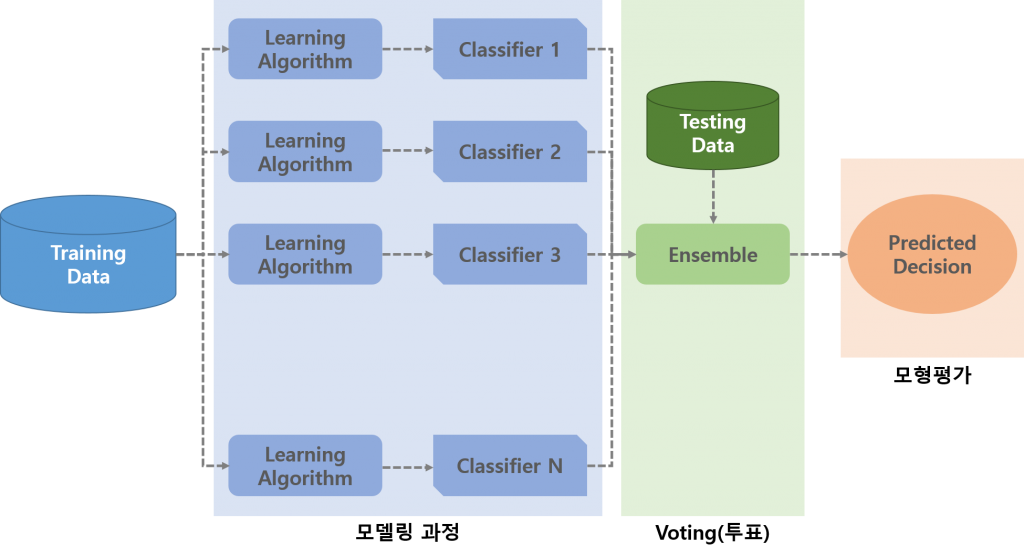
### 나. 앙상블학습 수행 단계
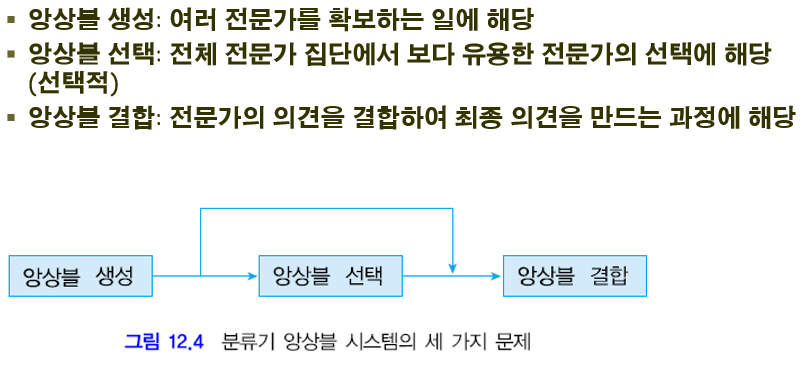
## Ⅲ. 앙상블학습의 일종, Bagging 개념
### 가. Bagging 개념
- 훈련집합을 들 가운데 훈련 튜플을 뽑는 방법을 균일한 확률 분포에 따라 반복적으로 셈플링을 해서 모델을 여러 개 만들어 Voting(투표)을 통해 최종 모델을 만드는 기법
- Bagging은 여러 번의 sampling을 통해 분산을 줄여 모델 변동성을 감소시키는 방법
### 나. Bagging 특징
- 모델링 후 평균 및 다중투표 연산으로 모델 도출
- 데이터의 결측치가 존재할 경우 우수
### 다. Bagging 수행 개념도
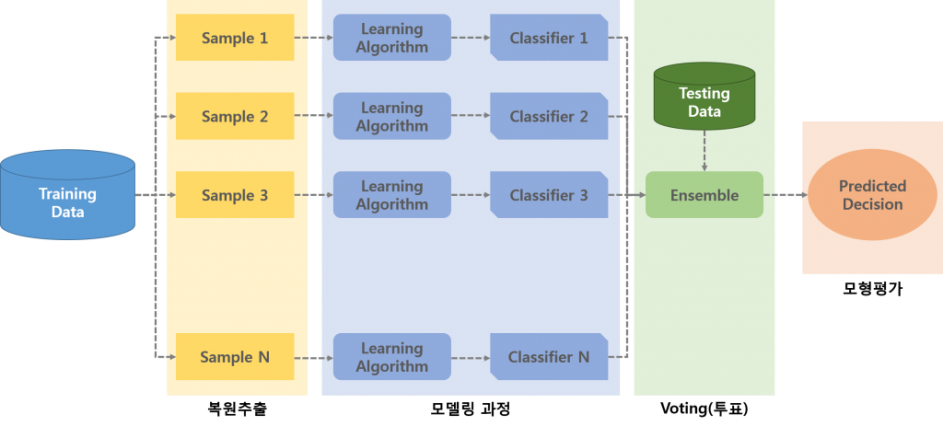
### 라. Bagging 수행 단계
1) Row data에서 bootstrap 데이터 추출
2) 추출을 반복하여 n개의 데이터 생성
3) 각 데이터를 각각 모델링 하여 모델 생성
4) 단일 모델을 결합하여 배깅 모델 생성( 다수투표 OR 평균치) ## Ⅳ. 앙상블학습의 일종, Boosting 개념 ### 가. Boosting 개념 - 모델에서 오분류한 학습데이터를 다음 모델이 빌드될때 학습 튜플로 선택되어질 가능성을 높여줘서 다음 모델에서 오류에 대한 보완하는 기법 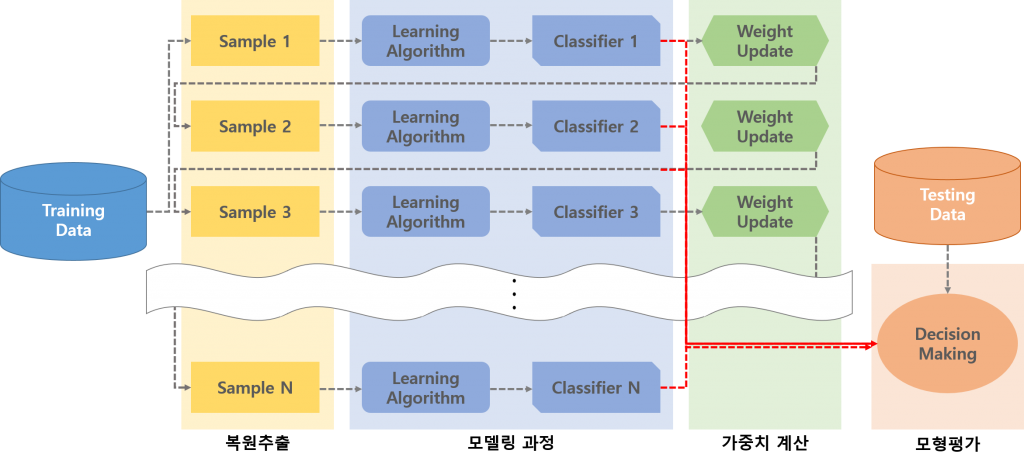 - Boosting은 잘못 분류된 데이터에 집중해 모델의 정확도를 향상시키는 **앙상블 기법의 하나** ### 나. Boosting 특징 - 가중치 선형결합을 이용하여 모델의 정확도 향상 - 데이터 수가 많은 경우에 유용함 ### 다. Boosting 수행 순서 1) Row data에 동일가중치로 모델 생성
2) 생성된 모델로 인한 오분류 데이터 수집
3) 오분류 데이터에 높은 가중치 부여
4) 과정 반복을 통하여 모델의 정확도 향상 ### 라. bagging 과 boosting 의 비교 |항목 | Bagging | Boosting |
| -------- | -------- | -------- |
| 수행원리 | 샘플링에 의한 결합 | 가중치 재조정에 의한 반복 |
| 수행목적 | 모델의 변동성(분산)을 감소 | 모델의 정확도 향상 |
| 적용연산 | 평균, 다중투표 | 가중치 선형 결합 |
| 초기모델 | Bootstrap 모델 (개별 모델) | Weak classification 모델 |
| 최종모델 | Bagging 모델 (결합 모델) | Strong classification 모델 |
| 분류성능 | 데이터에 결측치가 존재할 경우 우수 | 데이터의 수가 많을 경우 우수 |
- 데이터 마이닝에서 분류문제를 해결하고자 할 때 중요한 문제는 주어진 데이터를 이용해 목표변수를 가장 잘 예측할 수 있는 모델을 생성하는 것이므로, 데이터 특성에 따라 모델을 생성하는 알고리즘의 선택적 적용이 필요함
## Ⅴ. 앙상블학습의 일종, 랜덤포레스트
### 가. 랜덤포레스트(Random Forest) 개념
- 여러 개의 결정트리들을 임의적으로 학습하는 방식의 앙상블 방법으로서, 배깅(bagging)보다 더 많은 임의성을 주어 학습기들을 생성한 후 이를 선형 결합하여 최종 학습기를 만드는 방법
- 다수의 결정 트리를 구성하는 학습 단계와 입력 벡터가 들어왔을 때 분류하거나 예측하는 테스트 단계로 구성되어있는 기계학습방법
### 나. 랜덤 포레스트 부각 배경
| 단계 | 내용 |
| -------- | -------- |
| 의사결정 트리의 한계존재 | - 결과 또는 성능의 변동폭이 크다는 문제 및 학습데이터에 따라 생성되는 결정트리가 크게 달라져 일반화하기 어려운 과적합(overfitting)문제
- 계층적 접근방식으로서 중간에 에러발생 시 다음단계로 에러가 전파 | | 과적합 문제 극복필요 | - 임의화 기술을 통해 각 일반화 성능을 향상시켜 과적합문제 극복의 필요 | - Random Forest의 경우 트리들의 편향은 그대로 유지가 되면서, 분산은 감소하기 때문에 보다 안정적(일반화)이며 정확도 성능이 향상 ※ 과적합(overfitting)문제 : 감독학습(Supervised Learning)에서 과거의 학습데이터에 대해서는 잘 예측하지만 새로 들어온 데이터에 대해서 성능이 떨어져서 일반화가 어려운 문제 ### 다. 랜덤 포레스트 개념 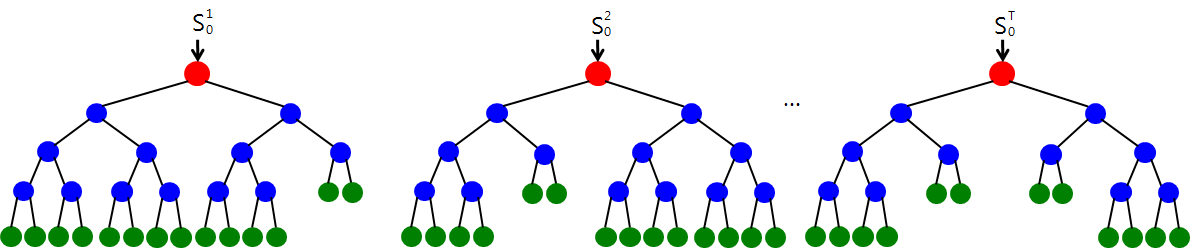 ### 라. 랜덤 포레스트 절차 |단계 | 내용 |
| -------- | -------- |
| 데이터집합생성 | - 부트스트랩(bootstrap)을 통해 T개의 훈련데이터 집합 생성 |
| 훈련 | - T개의 기초분류기(tree)들을 훈련시킨다 |
| 결합 | - 기초분류기(tree)들을 하나의 분류기(random forest)로 결합(평균 또는 과반수투표 방식을 이용) |
2) 추출을 반복하여 n개의 데이터 생성
3) 각 데이터를 각각 모델링 하여 모델 생성
4) 단일 모델을 결합하여 배깅 모델 생성( 다수투표 OR 평균치) ## Ⅳ. 앙상블학습의 일종, Boosting 개념 ### 가. Boosting 개념 - 모델에서 오분류한 학습데이터를 다음 모델이 빌드될때 학습 튜플로 선택되어질 가능성을 높여줘서 다음 모델에서 오류에 대한 보완하는 기법  - Boosting은 잘못 분류된 데이터에 집중해 모델의 정확도를 향상시키는 **앙상블 기법의 하나** ### 나. Boosting 특징 - 가중치 선형결합을 이용하여 모델의 정확도 향상 - 데이터 수가 많은 경우에 유용함 ### 다. Boosting 수행 순서 1) Row data에 동일가중치로 모델 생성
2) 생성된 모델로 인한 오분류 데이터 수집
3) 오분류 데이터에 높은 가중치 부여
4) 과정 반복을 통하여 모델의 정확도 향상 ### 라. bagging 과 boosting 의 비교 |
- 계층적 접근방식으로서 중간에 에러발생 시 다음단계로 에러가 전파 | | 과적합 문제 극복필요 | - 임의화 기술을 통해 각 일반화 성능을 향상시켜 과적합문제 극복의 필요 | - Random Forest의 경우 트리들의 편향은 그대로 유지가 되면서, 분산은 감소하기 때문에 보다 안정적(일반화)이며 정확도 성능이 향상 ※ 과적합(overfitting)문제 : 감독학습(Supervised Learning)에서 과거의 학습데이터에 대해서는 잘 예측하지만 새로 들어온 데이터에 대해서 성능이 떨어져서 일반화가 어려운 문제 ### 다. 랜덤 포레스트 개념  ### 라. 랜덤 포레스트 절차 |