밀도추정방식 DBSCAN Clustering
태그 : 밀도추정방식
- 개념
- 밀도추정 방식 Clustering, noise, border, core DBSCAN(Density Based Spatial Clustering with Application Noise)의 정의 – K-Means 군집의 한계인 오목한 형태의 데이터를 군집화하기 위해, 데이터의 밀도를 기준으로 인스턴스들을 공간적으로 군집화하는 기법
## Ⅰ. 밀도 기반의 공간적 군집화, DBSCAN의 개요
### 가. DBSCAN(Density Based Spatial Clustering with Application Noise)의 정의
- K-Means 군집의 한계인 오목한 형태의 데이터를 군집화하기 위해, **데이터의 밀도를 기준**으로 **인스턴스들을 공간적으로 군집화**하는 기법
### 나. 특징
- 노이즈 및 아웃라이어 데이터 식별에 강함
- 밀도 있게 연결되어 있는 데이터의 집합
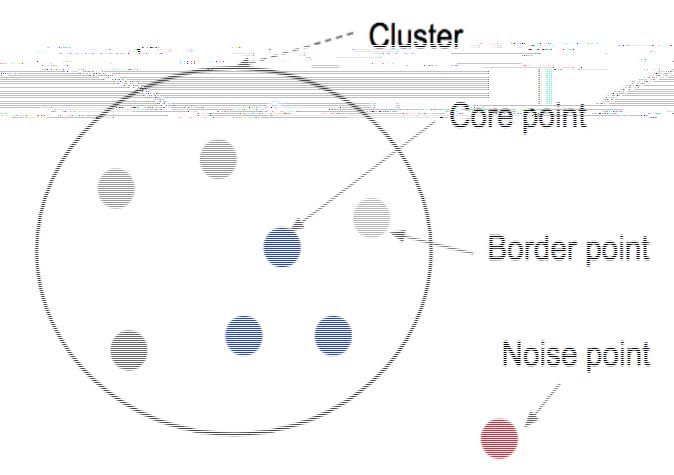
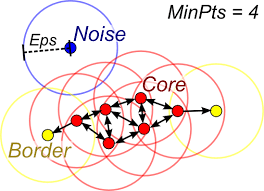
## Ⅱ. DBSCAN의 구성도 및 구성요소
### 가. DBSCAN의 구성도
| 이미지 1 | 이미지 2 |
| -------- | -------- |
| | |
### 나. DBSCAN의 구성요소
| 구성요소 | 설명 | 핵심 |
| -------- | -------- | -------- |
| Core point | - 일정 기준 이상의 밀도를 갖는 데이터(점)
- Core -> core로 탐색 | - n개 이상의 이웃 점을 갖는 데이터 | | Noise Point | - 일정 기준 미만의 밀도를 갖고, 군집에도 소속되지 않은 데이터(점) | - 어떤 군집에도 속하지 않음 | | Border point | - 일정 기준 미만의 밀도를 갖지만, 군집에 소속되어 있는 데이터
- Border를 만나면 군집에서 탐색 중지| - 군집 탐색 중지 | | ε(epsilon) | - 주어진 개체들의 반경
- 밀도: ε(epsilon) 안에 있는 다른 좌표 점의 수 | - 거리 기준 | | MinPts | - ε 반경내 군집 위해 필요한 객체 수
- 어떤 좌표점이 Cluster를 형성 할 수 있는 최소 좌표 점의 수| - 밀도 기준값 | ## Ⅲ. DBSCAN의 생성 절차 |절차 | 개념도 | 설명 |
| -------- | -------- | -------- |
| 기본상태 |  | – 좌표 공간에 학습 데이터의 표시
– ε (epsilon) : 주어진 객체들의 반경
– minPts : 군집 최소수
– ε 반경 내 minPts개가 존재해야 군집 판단 | | 군집생성 | 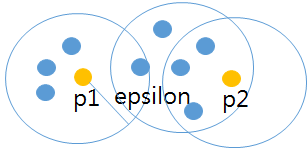 | – 임의 점 p1, p2 등에서 ε 반경 내 minPts 만족 시 군집| | Noise 분류 | | – 임의 점 p1 에서 ε 반경 내 p2 미 존재 시 Noise로 분류
– 한 점의 밀도가 MinPts 이상이면 Core, 미만이면 Noise로 정의| | 군집완성 |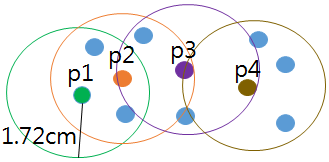 | – Cluster 구성 후 이웃 점을 차례로 방문하면서 Core인지를 판단(P1 → P2 → P3 → P4, 즉 P1과 P4는 같은 Cluster)
– 각 점에서 ε 반경 내 minPts 충족하는 객체집합(군집) 완성| ## Ⅳ. DBSCAN의 장단점과 K-Measns와의 처리 결과 비교 ### 가. DBSCAN의 장단점 |장점 | 단점 |
| -------- | -------- |
| – 군집개수 정의 필요 없음
– 임의 모양의 군집 생성
– 잡음(Noise) 개념 존재
– 2개의 매개변수만 필요 | – 유클리디안 거리 이용하여 ε 산출이 어려움
– 다차원 및 고밀도 데이터의 군집화 어려움 | ### 나. DBSCN과 K-Means와의 처리 결과 비교 |장점 | 단점 |
| -------- | -------- |
|  | – K-means는 동심원 모양으로 데이터가 모여 있거나
반달 모양으로 클러스터를 형성하고 있으면 클러스터의
중심으로부터 거리 기준으로 분류하는데 적합
– DBSCAN은 코어 데이터들을 계속 밀도 있게
연결하여 나아가 동일한 클러스터로 판단하기
때문에 직관적 관점에서 레이블이 없는 두 개의
클러스터에 적합|
- Core -> core로 탐색 | - n개 이상의 이웃 점을 갖는 데이터 | | Noise Point | - 일정 기준 미만의 밀도를 갖고, 군집에도 소속되지 않은 데이터(점) | - 어떤 군집에도 속하지 않음 | | Border point | - 일정 기준 미만의 밀도를 갖지만, 군집에 소속되어 있는 데이터
- Border를 만나면 군집에서 탐색 중지| - 군집 탐색 중지 | | ε(epsilon) | - 주어진 개체들의 반경
- 밀도: ε(epsilon) 안에 있는 다른 좌표 점의 수 | - 거리 기준 | | MinPts | - ε 반경내 군집 위해 필요한 객체 수
- 어떤 좌표점이 Cluster를 형성 할 수 있는 최소 좌표 점의 수| - 밀도 기준값 | ## Ⅲ. DBSCAN의 생성 절차 |
– ε (epsilon) : 주어진 객체들의 반경
– minPts : 군집 최소수
– ε 반경 내 minPts개가 존재해야 군집 판단 | | 군집생성 |  | – 임의 점 p1, p2 등에서 ε 반경 내 minPts 만족 시 군집| | Noise 분류 | | – 임의 점 p1 에서 ε 반경 내 p2 미 존재 시 Noise로 분류
– 한 점의 밀도가 MinPts 이상이면 Core, 미만이면 Noise로 정의| | 군집완성 | | – Cluster 구성 후 이웃 점을 차례로 방문하면서 Core인지를 판단(P1 → P2 → P3 → P4, 즉 P1과 P4는 같은 Cluster)
– 각 점에서 ε 반경 내 minPts 충족하는 객체집합(군집) 완성| ## Ⅳ. DBSCAN의 장단점과 K-Measns와의 처리 결과 비교 ### 가. DBSCAN의 장단점 |
– 임의 모양의 군집 생성
– 잡음(Noise) 개념 존재
– 2개의 매개변수만 필요 | – 유클리디안 거리 이용하여 ε 산출이 어려움
– 다차원 및 고밀도 데이터의 군집화 어려움 | ### 나. DBSCN과 K-Means와의 처리 결과 비교 |
반달 모양으로 클러스터를 형성하고 있으면 클러스터의
중심으로부터 거리 기준으로 분류하는데 적합
– DBSCAN은 코어 데이터들을 계속 밀도 있게
연결하여 나아가 동일한 클러스터로 판단하기
때문에 직관적 관점에서 레이블이 없는 두 개의
클러스터에 적합|