Word2vec
태그 : Word2vec
- 개념
- Wordembedding, CBOW, Skip-gram, one-hot-encoding Word2vec 정의 - 단어의 의미 파악 및 단어간 유사성을 찾기 위해, 말뭉치를 입력받아 word embedding이라는 벡터로 표현하여 분석하는 인공신경망 - 2013년 구글에서 발표된 연구로 만든 Continuous Word Embedding 학습 모형
## Ⅰ. 다차원 벡터를 이용한 자연어 분석. Word2vec 개요
### 가. Word2vec 정의
- 단어의 의미 파악 및 단어간 유사성을 찾기 위해, 말뭉치를 입력받아 word embedding이라는 벡터로 표현하여 분석하는 인공신경망
- 2013년 구글에서 발표된 연구로 만든 Continuous Word Embedding 학습 모형
### 나. One-hot-encoding의 한계 및 Word2vec의 특징
1) One-hot-encoding의 한계
| 구분 | 내용 |
| -------- | -------- |
| 사례 | [감자, 딸기, 사과, 수박] 에서 사과 표현 |
| One-hot-encoding | [0, 0, 1, 0] |
| 가능한 기능 | 해당 단어의 유무파악 (스팸메일 분류에서 많이 사용됨) |
| 불가능 기능 | 해당 단어와 다른 단어가 어떤 차이점을 가지는가 판단 불가 |
| 개념도 | 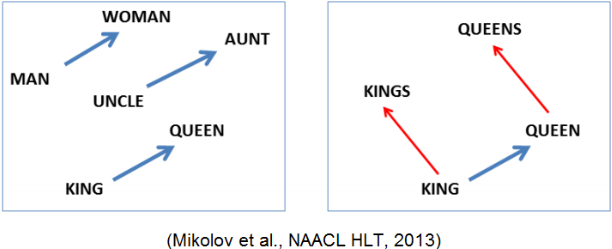 |
2) Word2vec의 특징
| 구분 | 내용 | |
| -------- | -------- | -------- |
| 착안 | 단어 자체가 가지는 의미를 다차원 공간에서 벡터화. (수백 차원) | |
| 특징 | 단어가 실수공간에 위치
벡터로 수치화 | - 각 단어 사이의 유사도 측정 가능. (코사인 유사도)
- 여러 단어에 대해 평균 등 수치적 처리 가능
벡터 연산을 이용한 추론 가능| | 용도 | 단어간 유사성 찾기
단어의 의미 파악
문장, 문서 분류
(문서 군집화 word2vec 으로 수행하면)| 유사한 단어일수록 가까운 거리에 위치
데이터의 양이 충분하도록 학습
1) 검색엔진에서 문서의 분야별 검색(과학, 법률, 경제)
2) 문장의 감석분석
3) 추천시스템| 코사인 유사도 : 두 벡터의 각도를 측정. (두 벡터가 이루는 각도가 0인 경우 최대값 1이 도출) ## Ⅱ. Word2vec의 학습모델 및 학습의 결과 ### 가. Word2vec의 학습모델 (word embedding model) |구분 | CBOW (Continous Bag Of Words) | Skip-gram |
| -------- | -------- | -------- |
| 개념도 | 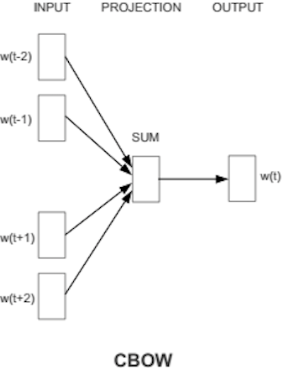 | 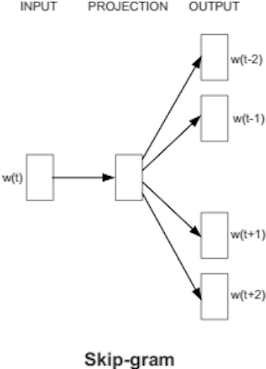 |
| 개념 | 주변 단어가 만드는 맥락을 이용해 타겟 단어를 예측 | 한 단어를 기준으로 주변에 올 수 있는 단어를 예측 |
| 사례 | 집 앞 편의점에서 아이스크림을 사 먹었는데, __ 시려서 너무 먹기가 힘들었다 → __ = 이 | 서울 – 한국, 문재인
도쿄 – 일본, 아베
중국 – 베이징, 시진핑 | | 학습과정 | 1) 한 단어에 이미 할당된 벡터(word embedding) 이 있다고 가정.
2) 이 값을 이용, 주변 문맥을 얼마나 정확하게 예측하는지 계산.
3) 정확도가 나쁜경우(조정필요시) 오차에 따라 벡터의 값을 업데이트.
- 한 단어를 기준으로, 단어 주변의 문맥을 참고, 현재 embedding vector가 얼마나 정확한지, 오차값은 어느정도인지 알아냄.
- 어떤 두 단어가 비슷한 문맥에서 꾸준히 사용된다면 두 단어의 벡터값은 비슷하게 됨.
ex) 소나무 근처에 박달나무, 은행나무등이 비슷한 곳에 모임.
전쟁, 갈등, 불화 등은 다른곳에 모임.| | ### 나. Word2vec의 학습 결과 1) 숫자, 동물을 word embedded(벡터) 로 표현한 결과 |숫자, 동물 |
| -------- |
| 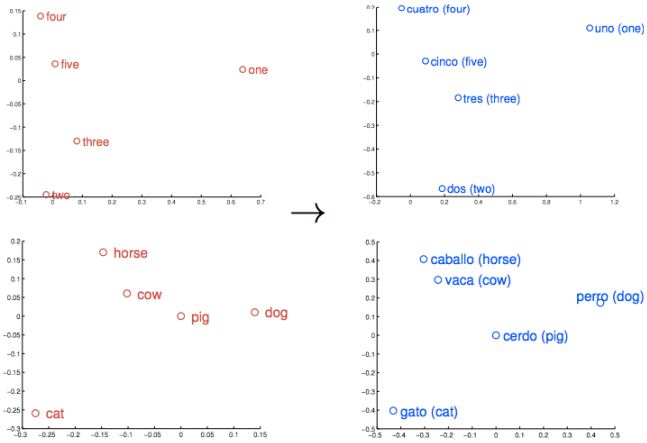 |
| 의미 : 1. 비슷한 물체나 개념은 가까이에 위치.
2. 단어의 상대적인 의미와 관계도 벡터로 표시됨| 관계를 이용하면 유사성을 넘어서 더 복잡한 일을 할 수 있음 2) 국가와 수도를 표현한 결과를 PCA를 이용하여 프로젝션 |국가와 수도 |
| -------- |
| 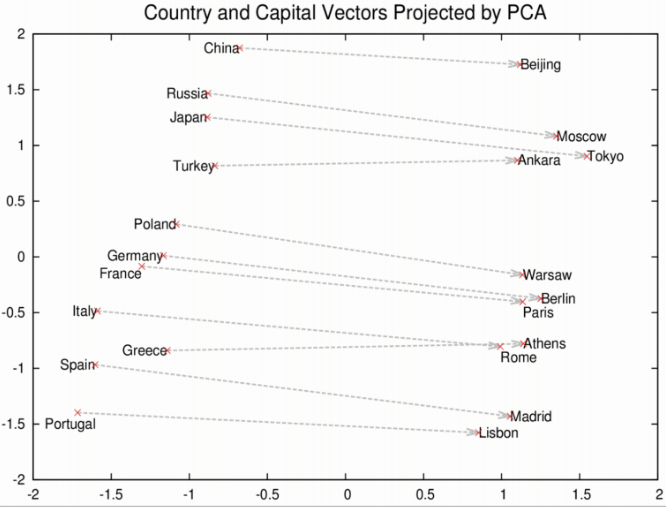 |
| 의미 : 1. 로마, 파리, 베를린, 베이징은 전부 나라의 수도이며 비슷한 의미와 맥락에서
쓰이기 때문에 가까이 위치.
2. 로마와 이탈리아, 베이징과 중국은 모두 수도와 국가의 관계이므로 각각에
로마-이탈리아와 베이징-중국의 벡터 공간에서의 관계도 유사하게 학습 | | | 활용 :질의 형식 : **EV1 – EV2 + EV3** (비례식 설명 : EV1:EV2 = EV3 : **?**)
- EV = Embedding Vector
사례) 로마 - 이탈리아 + 중국 -> 결과 : **베이징** | |
벡터로 수치화 | - 각 단어 사이의 유사도 측정 가능. (코사인 유사도)
- 여러 단어에 대해 평균 등 수치적 처리 가능
벡터 연산을 이용한 추론 가능| | 용도 | 단어간 유사성 찾기
단어의 의미 파악
문장, 문서 분류
(문서 군집화 word2vec 으로 수행하면)| 유사한 단어일수록 가까운 거리에 위치
데이터의 양이 충분하도록 학습
1) 검색엔진에서 문서의 분야별 검색(과학, 법률, 경제)
2) 문장의 감석분석
3) 추천시스템| 코사인 유사도 : 두 벡터의 각도를 측정. (두 벡터가 이루는 각도가 0인 경우 최대값 1이 도출) ## Ⅱ. Word2vec의 학습모델 및 학습의 결과 ### 가. Word2vec의 학습모델 (word embedding model) |
도쿄 – 일본, 아베
중국 – 베이징, 시진핑 | | 학습과정 | 1) 한 단어에 이미 할당된 벡터(word embedding) 이 있다고 가정.
2) 이 값을 이용, 주변 문맥을 얼마나 정확하게 예측하는지 계산.
3) 정확도가 나쁜경우(조정필요시) 오차에 따라 벡터의 값을 업데이트.
- 한 단어를 기준으로, 단어 주변의 문맥을 참고, 현재 embedding vector가 얼마나 정확한지, 오차값은 어느정도인지 알아냄.
- 어떤 두 단어가 비슷한 문맥에서 꾸준히 사용된다면 두 단어의 벡터값은 비슷하게 됨.
ex) 소나무 근처에 박달나무, 은행나무등이 비슷한 곳에 모임.
전쟁, 갈등, 불화 등은 다른곳에 모임.| | ### 나. Word2vec의 학습 결과 1) 숫자, 동물을 word embedded(벡터) 로 표현한 결과 |
2. 단어의 상대적인 의미와 관계도 벡터로 표시됨| 관계를 이용하면 유사성을 넘어서 더 복잡한 일을 할 수 있음 2) 국가와 수도를 표현한 결과를 PCA를 이용하여 프로젝션 |
쓰이기 때문에 가까이 위치.
2. 로마와 이탈리아, 베이징과 중국은 모두 수도와 국가의 관계이므로 각각에
로마-이탈리아와 베이징-중국의 벡터 공간에서의 관계도 유사하게 학습 | | | 활용 :질의 형식 : **EV1 – EV2 + EV3** (비례식 설명 : EV1:EV2 = EV3 : **?**)
- EV = Embedding Vector
사례) 로마 - 이탈리아 + 중국 -> 결과 : **베이징** | |