인덱스(Index)
태그 :
- 개념
- 인덱스를 이용하여 테이블의 존재하는 데이터 검색 속도를 빠르게 하기 위한 목적으로 테이블의 저장된 로우(ROW)를 식별 가능하도록 구조화된 형태의 테이블과 별도의 체계로 저장한 데이터베이스 오브젝트
1. 데이터 검색속도 향상을 위한 데이터베이스 인덱스의 개요.
가. 인덱스(Index)의 정의
- 인덱스를 이용하여 테이블의 존재하는 데이터 검색 속도를 빠르게 하기 위한 목적으로 테이블의 저장된 로우(ROW)를 식별 가능하도록 구조화된 형태의 테이블과 별도의 체계로 저장한 데이터베이스 오브젝트.
나. 인덱스의 특징
|
특징 |
내용 |
비고 |
|
성능향상 |
-데이터베이스 테이블에 접근하는 트랜잭션의 성능 향상이 목적임 -조회 성능향상이 주목적, 입력/수적/삭제 성능은 더 저하됨 |
-조회 성능 향상 |
|
독립성 |
-테이블에 저장구조와 별도로 인덱스만 저장할 수 있음 |
-독립적 인덱스 저장구조 |
|
알고리즘 |
-Tree 구조, Hash 함수 등 적용, 알고리즘을 적용하여 생성 |
-알고리즘 |
|
Trade-Off |
-조회 vs 입력/수정/삭제 성능을 고려하여 인덱스 생성요구 |
-인덱스 생성의 효율성 고려 |
다. 인덱스의 필요성
|
관점 |
구분 |
세부 내용 |
|
개발자 |
-개발생산성 향상 -유지보수 비용 절감 |
-응용시스템 개발 속도 증가 -장기적 관점의 비용 절감 효과 |
|
사용자 |
-응답속도 향상 -고객만족도 개선 |
-정성적, 정량적 수행 속도 향상 -실질적 고객 만족도 상승 효과 |
|
시스템 |
-가용성 향상 -신뢰성 증진 |
-사용 요구에 대한 적시 사용 지원 -요구 기능에 대한 정확한 응답 |
2. 인덱스 구조의 분류 및 비교
가. 데이터 베이스 인덱스 구조의 분류
|
분류 기준 |
세부 인덱스 구조 |
|
인덱스 형태 |
트리 기반 인덱스, 해쉬 기반 인덱스, 비트맵 인덱스 |
|
활용 목적 |
함수 기반 인덱스, 조인 인덱스, 도메인 인덱스 |
- 인덱스는 데이터 베이스의 검색 속도 향상을 위한 DB객체로서 구조 및 활용 목적에 따라 다양함
나. 인덱스 형태별 인덱스 구조 비교
|
항목 |
트리 기반 인덱스 |
해쉬 기반 인덱스 |
비트맵 인덱스 |
|
목적 |
OLTP 범위 검색 |
OLTP 키 검색 |
DW, Mart 데이터 검색 |
|
구성 요소 |
Root, Leaf 노드 |
버켓, 해쉬함수, 해쉬테이블 |
비트맵 인덱스 |
|
종류 |
1차원:B-Tree,B*-Tree,T-Tree 다차원:R-Tree, 3DR-Tree |
해슁, 동적해슁, 확장해슁, 선형해슁 |
비트맵인덱스
|
|
사례 |
|
|
|
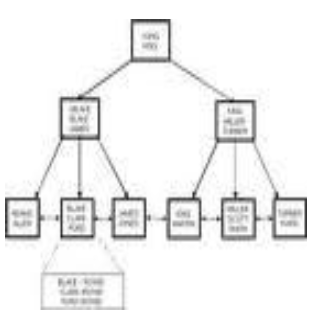
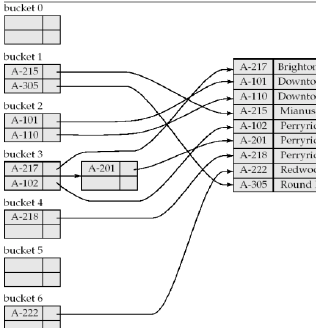
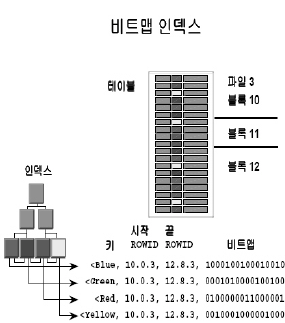
다. 인덱스 활용 목적별 인덱스 구조 비교
|
항목 |
함수 기반 인덱스 |
비트맵 조인 인덱스 |
도메인 인덱스 |
|
목적 |
함수, 수식 기반 인덱스 사용 |
조인 결과의 검색 성능 향상 |
개발자 정의형 인덱스 타입 |
|
기반 인덱스 |
트리 및 비트맵 인덱스 |
비트맵 인덱스 |
InterMedia text Index |
|
특징 |
산술식, PL/SQL 함수, SQL 함수에 적용 |
조인 결과를 비트맵 인덱스의 대상 데이터로 구성 |
인덱스 시스템의 확장성 향상 |
라. 인덱스 유형
|
밀집 인덱스(dense index) : 파일 내의 모든 탐색 키에 대해 하나의 인덱스 레코드를 갖고 있는 인덱스
|
|
희소 인덱스(sparse index) : 파일의 레코드 중 일부에 대해서만 인덱스 레코드가 생성되는 인덱스 (블록 포인터)
|
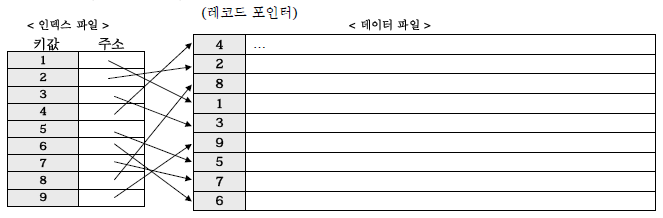
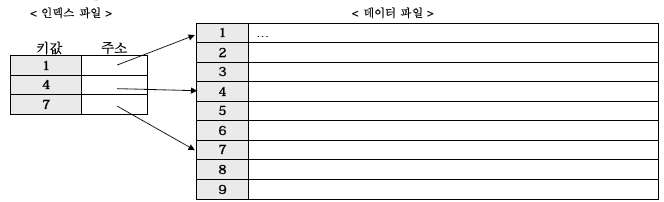
마. 인덱스 종류
1) 기본 인덱스 : 기본 키(Primary Key)를 포함하는 필드들에 대한 인덱스를 말하며, 중복된 키값들이 나타날 수 없다. (필드값이 유일한 순서필트에 적용)

2) 클러스터링 인덱스 : 파일 내의 레코드들이 각 레코드에 대해 유일한 값을 가지지 않는 키가 아닌 필드에 대해 물리적으로 정렬되어 있는 순서 파일에 대해 정의할 수 있으며, 이 필드를 클러스터링 필드라고 하며, 클러스터링 필드값이 같은 레코드를 검색하기 위한 인덱스를 클러스터링 인덱스 라고 한다. (필트값이 중복된 순서 필트에 적용)

3) 보조 인덱스 : 인덱스로 사용하는 검색 키가 파일에 저장되어 있는 레코드의 순서와 다른 순서를
정의하는 인덱스를 말함. 보조 인ㄴ덱스는 후보 키나 모든 레코드에 대한 유일한 값을 갖는 필드 또는 중복된 값을 갖는 키가 아닌 필드에 대해 정의할 수 있으며, 이 필드를 보조키(secondary key)라 함 (필드값이 중복되거나 유일한 비순서 필드에 적용)

바. 인덱스 순차파일
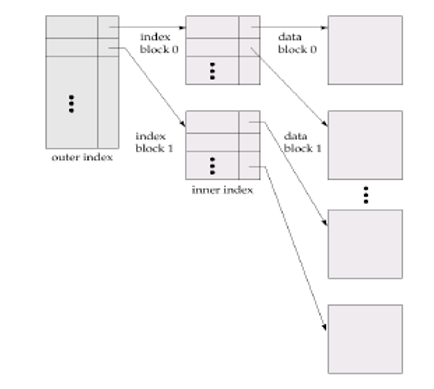
※ 순차 파일(순차접근 지원)과 직접 파일(직접 접근 지원)을 결합한 형태
- 순차 데이터 파일 (sequential data file)
ㆍ레코드가 순차적으로 정렬
ㆍ레코드 집합 전체에 대한 순차 접근 요구를 지원하는데 사용
ㆍ 순차 접근 방법 (sequential access method)
- 인덱스(index)
ㆍ레코드들에 대한 포인터를 가짐
ㆍ개별 레코드들에 대한 임의 접근 요구를 지원하는데 사용
ㆍ직접 접근 방법(direct access method)
※ 인덱스된 순차파일 (Indexed Sequntial File)
- 다단계 인덱스를 활용하는 이유 : 탐색수를 줄이기 위해
|
구분 |
ISAM |
VSAM |
|
특성 |
ㆍ물리적 특성에 종속적 |
ㆍ물리적 특성에 독립적 |
|
파일구성 |
ㆍ인덱스 영역 (트랙,실린더,마스터) ㆍ기본 데이터 영역 ㆍ오버 플로우 영역 (실린더, 독립) |
ㆍ인덱스 세트 ㆍ순차 세트 |
|
탐색방법 |
ㆍ직결탐색 : 마스터인덱스 ㅡ> 실린더인덱스,트랙인덱스를 통해 각 트랙의 데이터 탐색 ㆍ순차탐색 : 트랙인덱스를 통해 각 트랙의 데이터 탐색 |
ㆍ직접탐색 : 인덱스세트 -> 순차세트를 통해 제어 구간에 데이터 탐색 ㆍ순차탐색 : 순차세트를 통해 제어구간의 데이터를 탐색하며, 순차세트의 연결리스트를 이용 |
사. 다중 키 파일(Multikey file)
- 하나의 데이터파일에 여러 개의 인덱스를 제공하여 데이터를 탐색하는 방법
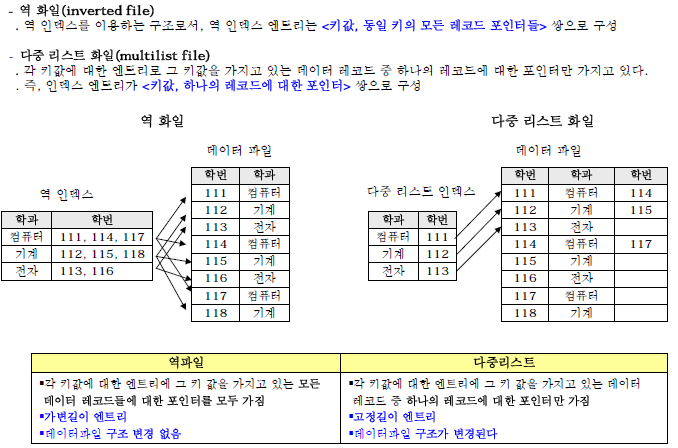
- 역파일(inverted file
ㆍ역 인덱스를 이용하는 구조로서, 여겨 인덱스 엔트리는 <키값, 동일 키의 모든 레코드 포인터들> 쌍으로 구성
- 다중 리스트 파일(multilist file)
ㆍ각 티값에 대한 엔트리로 그 키값을 가지고 있는 데이터 레코드 중 하나의 레코드에 대한 포인터만 가지고 있다.
ㆍ즉, 인덱스 엔트리가 <키값, 하나의 레코드에 대한 포인터> 쌍으로 구성
3. 인덱스의 선택 지침 및 인덱스튜닝이 발생하는 사유
가. 인덱스의 선택 지침
|
구분 |
선택 지침 |
세부 내용 |
|
시스템 측면 |
테이블 크기 |
-일정크기 이상의 테이블에 인덱스 생성 (6블럭이상) |
|
카디널리티 |
-인덱스컬럼의 카디널리티가 3000건 미만인 경우 -무조건 분포도가 10% 이내인 경우 적용 지양 |
|
|
기본키/외래키 |
-조인의 연결고리가 되므로 인덱스 생성 |
|
|
비트맵 인덱스 |
-분포도가 나쁘면서 자주 사용 된다면 BITMAP 인덱스를 고려 |
|
|
운영 측면 |
조회 전용 |
가능한 수정이 빈번하지 않은 컬럼 |
|
ACCESS PATH |
조사된 엑세스 유형을 토대로 선정기준 마련 |
|
|
중복성 회피 |
하나의 컬럼이 여러 인덱스에 포함되지 않게 적용 |
|
|
부분 범위처리 |
부분 범위 처리 전용일 경우 분포도 나쁘더라도 선정 |
|
|
결합 인덱스 |
컬럼 선정에 유의(사용빈도->유일성->SORT유형) |
나. 물리적 설계 관점에서 인덱스 튜닝이 발생하는 이유
|
사유 |
세부 내용 |
사례 |
|
표준 미수립 |
데이터타입 및 길이, 용어표준 미정의 |
날짜데이터 타입 -> CHARACTER타입과 DATE타입 혼용 |
|
저장공간 계획 미수립 |
테이블,인덱스 등의 정확한 용량산정이 되지 않음 |
인덱스 블럭 포화로 인한 인덱스 리빌드 및 삭제 유발 |
|
엔티티 확장 정책 미비 |
잘못된 엔티티 간의 특수화,일반화,그룹화,상속화 |
관련 있는 SUB TYPE통합을 하지 않아 인덱스 증가 |
|
과도한 정규화 |
엔터티의 과도한 상세화로 인해 인덱스 수 증가 초래 |
엔터티가 세분화 되어 수행속도 감소 |
|
무결서 미정의 |
참조 무결성, 개체 무결성, 속성 무결성 등의 미정의 |
외래키 미 생성으로 인한 무결성 위배 |
|
인덱스의 잘못된 설계 |
인덱스선정지침 미 준수에 따른 효율성 저하 |
조회문에 자주 사용되는 컬럼 인덱스 미선정 |
|
데이터 특성 분석 미비 |
트랜잭션이 빈번한 데이터에 대한 인덱스 파라미터 설계 미비 |
잦은 트랜잭션 발생 인덱스의 리빌드 수행 |
다. 인덱스의 설계 순서
|
순서 |
설명 |
예시 |
|
1. 인덱스 대상 선정 |
-하나의 인스턴스가 수행하는 MULTI BLOCK READ 수가 16 으로 지정되어 있다면 테이블의 크기가 16 블럭 이상 일 때 인덱스를 설정 |
• 대상 컬럼 선정 • 대상 테이블 선정 • PK 인덱스 선정 • FK 인덱스 선정 • 대상 컬럼 선정 |
|
2. 인덱스 최적화 |
-인덱스 컬럼은 가능하면 수정이 자주 발생되지 않는 컬럼을 선정 -평균분포도가 10 ~ 15%이내 -한 테이블에 인덱스의 개수가 5 개 이내 |
• 인덱스효율검토 • 인덱스데이터타입 적용 • 인덱스정렬 • 클러스터링검토 |
|
3. 인덱스 정의서 작성 |
설계단계에서 예상되는 인덱스에 대해 정의 |
• 엔티티타입명 • 인덱스스페이스 • 인덱스유형 • 정렬 • 구분 등 기술 |
4. 결합 인덱스의 순서 및 고려사항
가. 결합 인덱스의 순서
- 액세스 패스 조건에 많이 사용되는 칼럼을 우선.
- ‘=’ 조건으로 사용되는 칼럼을 우선.
- 분포도가 좋은 칼럼을 우선.
- 자주 사용되는 sort의 순서로 결정.
- 해당 칼럼의 동일한 값이 적을수록 분포도가 좋다고 표현 함.
나. 결합 인덱스 추가시 고려사항
- 추가로 단독/싱글 인덱스의 경우 분포도가 좋은 칼럼은 단독적으로 생성하여 활용도를 향상 시킬 수 있음
- 결합/복제 인덱스의 경우 분포도는 우선 순위가 높은 편이 아님.
- 논리적 모델링에서 릴레이션이 만들어져 물리적 모델링에서 외부키(foreign key)로 사용된 칼럼에 대해서는 인덱스 생성을 권고.
- 모든 외부키에 대하여 Lock 결합을 피하기 위하여 인덱스가 생성되어야 함.
- 만약, 칼럼이 외부키에 포함되어 있고 그것을 위한 인덱스가 구성되어 있지 않다면 테이블의 무결성을 보장하기 위하여 지나친 Lock이 발생.
- 물리적 모델링에서 물리적인 FK를 사용하지 않더라도 논리적 모델링에 연결고리가 있었다면 인덱스 생성을 권고.