해싱개요
태그 :
- 개념
- 키 값에서 레코드가 저장되어 있는 주소를 직접 계산한 후 산출된 주소로 바로 접근이 가능하게 하는 것으로 원소 값으로 부터 저장 원소의 위치를 계산할 수 있는 테이블 구조를 통해 탐색, 삽입, 제거하는 방법
1. 대용량 데이터 검색/추출을 위한 해싱의 개요
가. 해싱(Hashing)의 정의
해싱은 키 값에서 레코드가 저장되어 있는 주소를 직접 계산한 후 산출된 주소로 바로 접근이 가능하게 하는 방법
원소 값으로부터 저장 원소의 위치를 계산할 수 있는 테이블 구조를 통해 탐색, 삽입, 제거하는 방법
다른 어떤 레코드도 참조하지 않고 원하는 목표 레코드를 직접 접근할 수 있게 하는 기법으로 해싱기법을 통해 만들어진 파일을 직접 화일(direct file) 또는 해시 파일(hash file)이라 함
나. 해시 함수(hashing function)
주어진 키 값으로부터 레코드가 저장되어 있는 주소를 산출해 낼 수 있는 수식을 의미하며, 키 값을 레코드의 물리적 주소로 사상시키는 사상함수(mapping function)라고도 함
다. 좋은 해시함수의 조건
계산이 빨라야 하고, 충돌이 적어야 하며, 고르게 분포할 수 있도록 주소를 만들어야 함
라. 해싱이 사용되는 분야
|
분 야 |
내 용 |
|
보안 분야 |
데이터의 위변조를 막기 위해 전자서명이나 보안 알고리즘에 사용 |
|
자료구조 분야 |
기억 공간에 저장된 정보를 보다 빠르게 검색하기 위해 절대번지나 상대번지가 아닌 해쉬 테이블을 생성하는 방식 |
2. 해싱의 개념도 및 주요개념
가. 해싱의 개념도
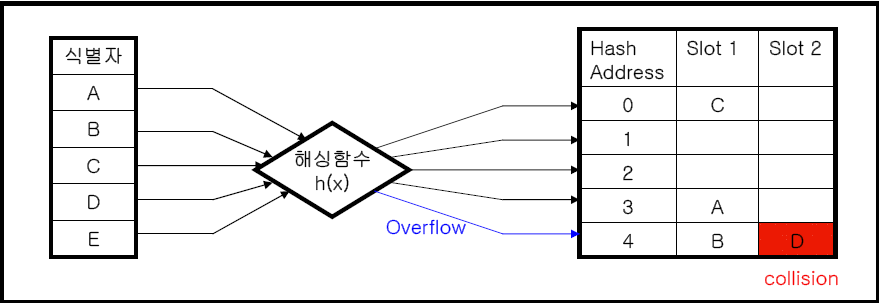
나. 해싱 관련 주요 개념
|
용 어 |
주요 개념 |
|
직접파일 (Direct File) |
해싱방법을 기초로 하여 만들어진 파일 레코드를 식별하기 위한 키 값과 저장 장치에 저장되어 있는 레코드 사이의 사상관계가 성립 되어야 함 |
|
해싱함수 |
Hashing Function 키 값으로부터 레코드의 물리적 주소로 사상시키는 사상 함수 |
|
해쉬 필드 해쉬 키 |
Hash Field, Hash Key 해싱함수가 레코드 주소를 계산하기 위해 사용하는 레코드의 키 값을 말함 해시함수의 입력값해시 필드해시 주소해수함수의 결과값 |
|
해싱표 (Table) |
Hashing Table 해시 키를 사용하여 계산된 주소임
|
|
버켓 |
Bucket 하나의 주소를 가지면서 하나 이상의 레코드를 저장할 수 있는 파일의 한 구역 크기는 같은 주소에 포함될 수 있는 레코드 수 여러 개의 슬롯으로 구성 |
|
슬롯 (slot) |
한 개의 레코드를 저장 할 수 있는 공간 |
|
충돌 |
서로 다른 두개의 키 값이 동일한 주소같은 버킷로 산출된 현상 |
|
동거자 |
동일한 주소로 산출된 두 키 값 |
|
오버플로우 |
더 이상 빈자리가 없는 과잉인데또 다른 레코드가 버켓에 저장되도록 해싱 |
|
적재밀도 |
실제 사용중인 키 값 갯수버킷 개수슬롯 개수 |
|
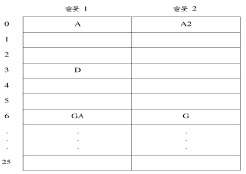
예 |
- b=26개의 버킷과 s=2인 해시 테이블 - n=10개, 적재밀도 =10/52 = 0.19 - 0부터 25까지의 숫자로 사상시킴 - GA와 G가 같은 버킷에 있음 - A와 A2가 같은 버킷에 있음 |
다. 해싱 함수에 적용되는 기술
|
기술 구분 |
내 용 |
|
제산함수 (Division) |
나머지를 구하는연산자를 이용하여 주소 값을 취하는 방식 나누고자 하는 값즉 제수는 해싱테이블의 크기를 나타냄 적재율은 70 ~ 80%가 적당 예) 123456789 mod 5003 = 2761 (물리적 주소) |
|
중간 제곱 함수 (Mid Square) |
키 값의 중간자리를 뽑아서 제곱한 후 상대 번지로 사용 제곱한 결과를 주소 공간의 크기에 맞도록 조정 예) 123456789 ×123456789 = 1524157 8750 190521 (4자리 물리주소) |
|
숫자 분석법(digit analysis) |
키 값이 되는 숫자의 분포를 이용하여 저장주소를 산출하는 방법 예) 키 값이 학번(년도/학과/주야구분/학생번호)이고 해시테이블 주소가 3자리인 경우 2008 04 1 03 2008 04 1 09 2008 04 1 12 => 가장 고르게 분포된 번호는 학생번호(2자리)와 주야구분(1자리)을 합쳐서 주소 생성 2008 04 2 07 2008 04 2 14 |
|
폴딩 함수 (Folding) |
키값을 주소와 같은 자릿수를 갖는 몇 개의 부분으로 나누어 이 부분들을 접어서 그 합을 구한 다음그 합에서 주소와 같으 자릿수만 취하는 방법
|
|
기수 변환 (Radix Coversion) |
주어진 키 값을 특정 진법으로 간주한 후 다른 진법으로 변환 값을 이용하는 기술임 |
|
기타 |
대수적 코딩 |
라. 해시 함수의 유형
|
유 형 |
주요 개념 |
적용 사례 |
|
폐쇄 해싱 (Closed Hashing) |
모든 레코드를 한 버켓에 저장시키고해싱함수로 버켓내 주소를 계산하는 방식정적 해싱 기법이 있음 |
|
|
개방 해싱 (Open Hashing) |
레코드의 증감에 적용하기 위해 동적으로 해싱함수가 교정되도록 한 기법 동적 해싱 기법 |
데이터베이스 시스템 |
3. 정적 해싱(Static Hashing) 기법
가. 정적 해싱(Static Hashing) 기법의 정의
-버켓 주소의 집합을 고정시켜 처리하는 해싱 기법임
-버킷(bucket) : 하나의 주소를 가지면서 하나 이상의 레코드 를 저장할 수 있는 화일의 한 구역
-버킷 크기 : 저장장치의 물리적 특성과 한번 접근으로 채취 가능한 레코드수 고려
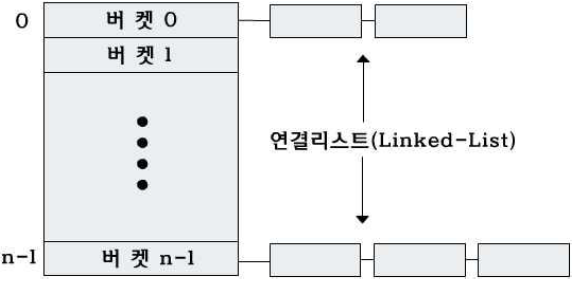
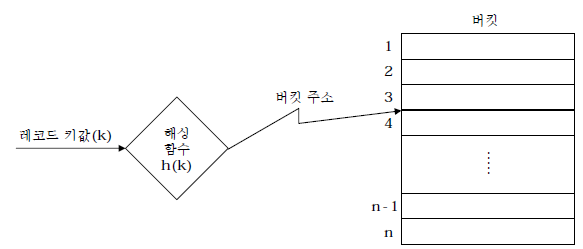
충돌(collision) : 상이한 레코드들이 같은 주소(버킷)로 변환
. 버킷 만원 - 오버플로우 버킷
. 한번의 I/O가 추가됨
나. 정적 해싱 기법의 특징
-현재의 파일 크기에 근거하여 해싱 함수 선택
-미래의 특정 시점의 파일 크기를 예상하여 해싱 함수 선택
-파일의 크기가 커짐에 따라 주기적으로 해싱 구조를 재구성 해야 함
다. 정적 해싱 함수의 종류
|
구분 |
내용 |
|
Mid-Square |
- 키 값을 제곱한 후에 중간에 몇 비트를 취해서 해쉬 테이블의 버킷 주소를 생성 - 버킷 주소가 고르게 분포
|
|
Division |
- 키 값을 소수로 나누어 나머지를 Hash Address로 사용 - 현재로서는 가장 좋은 방식 |
|
Folding |
-키 값을 동일한 길이의 여러 부분으로 분할해 분할된 부분을 더해서 Hash Address로 사용
|


라. 정적 해싱의 문제점 및 해결방안
|
구 분 |
문제점 |
내 용 |
|
문제점 |
Collision |
복수개의 키 값이 동일사용 |
|
Overflow |
빈 버켓이 없는 상태에가 다시 지정된 상태 |
|
|
해결방안 |
선형 검색법 |
충돌이 일어난 그 위치에서 테이블 순으로 차례대로 검색하여 첫 번째 빈 버켓 공간에 레코드 키를 저장하여 충돌을 해결함 |
|
2차 검색법 |
원래의 테이블 주소로 부터 다음 주소를 결정하는 거리만큼 떨어진 영역을 차례대로 검색하여 처음으로 발견되는 빈 버켓 공간에 저장 |
|
|
랜덤 검색법 |
충돌을 유발할 레코드 키를 저장할 수 있는 공간을 찾을 때까지난수를 적용하여 해시케이블의 홈 주소를 다음 주소로 선택하여 해결 |
|
|
체인 이용법 |
충돌이 발생한 레코드들을로 연결하는 방법으로 해시 테이블 자체는 포인터를 배열로 만들고같은 버켓에 할당되는 레코드들은 체인으로 연결
|

4. 동적/확장 해싱(Dynamic Hashing) 기법
가. 동적 해싱 기법
-데이터베이스가 확장 또는 축소되는데에 맞추어 해싱함수를 동적으로 변경 시키는 해싱기법(Overflow 발생시 2배수 확장)
-키 값을 사용하여 이진 트리를 동적으로 변화시킴
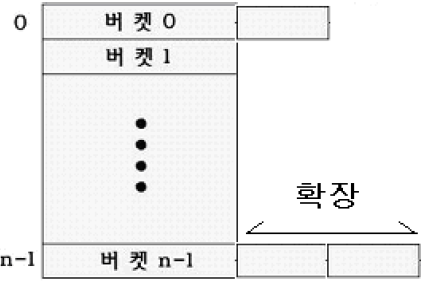
나. 확장 해싱(Extendible Hashing)의 개념
동적 해싱의 한 형태이며 트리의 깊이가 2인 특별한 경우
해싱구조의 재구성이 한번에 한 개의 버켓에서만 발생하므로, 상대적 부하경감
부가적인 접근구조 (디렉터리)를 저장하며, 해시함수 적용결과인 이진수 표현을 기반으로 함
입력되는 레코드의 수에 따라 버킷의 수가 변함
다. 확장성 해싱
부가적인 접근구조 (디렉터리)를 저장하며, 해시함수 적용결과인 이진수 표현을 기반으로 함
입력되는 레코드의 수에 따라 버킷의 수가 변함
라. 디렉토리
버킷들을 지시하는 2d 개의 포인터로서, 버킷을 주소를 나타내며, 헤더에 정수값 d를 저장 (d = 전역깊이)
마. 모조키(pseudokey) : 해싱 함수를 통해 일정 길이의 비트 스트링으로 나온 값(처음 d 비트를 인덱스로 사용)
바. 버킷 : 정수 값 p(<=d)가 저장된 헤더가 존재함
p = 지역 깊이 (local depth), 버킷에 저장된 레코드들의 모조키들이 처음부터 p비트까지 모두 동일
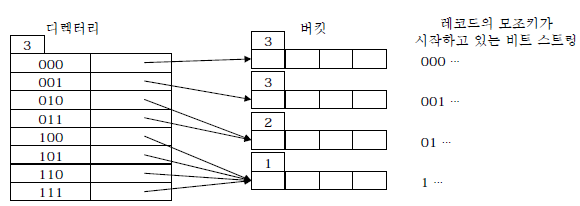
5. 동적/확장 해싱(Dynamic Hashing) 의 검색, 저장, 오버플로우 처리
가. 검색
1) 모조키의 처음 d비트를 디렉터리에 대한 인덱스로 사용
2) 접근된 디렉터리 엔트리는 목표 버킷에 대한 포인터를 제공
3) 검색 예
- 키 값 k → 모조키 101000010001
- 모조키의 처음 3비트(=d) 사용
. 디렉터리의 6번째(101) 엔트리를 접근
- 엔트리는 4번째 버킷에 대한 포인터
- 키 값 k를 가지고 있는 레코드가 저장되어있는 곳 ( p= 1 : 모조키 비트 1로 시작하는 레코드 저장)
나. 저장
- 모조키의 처음 d 비트를 이용 디렉터리 접근
- 포인터가 지시하는 버킷에 레코드 저장
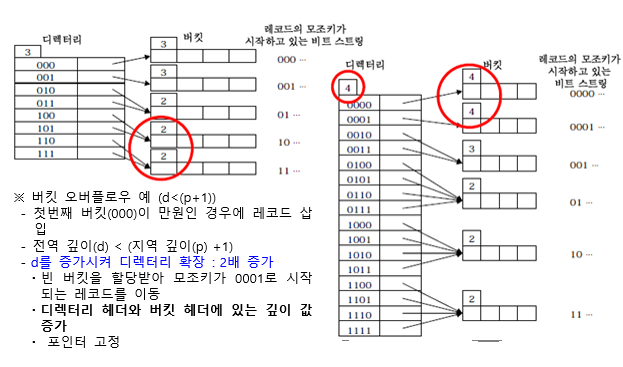
다. 오버플로우 처리
- 새로운 버킷을 생성 (d≥(p+1))
. 오버플로 버킷의 레코드들과 새로 저장할 레코드를 오버플로 버킷과 새로 할당한 버킷에 분산
. 기존 버킷과 새로 할당된 버킷의 깊이 값 p는 모두 (p+1)로 설정
- 디렉터리 오버플로우 (d<(p+1))
. 디렉터리 크기 증가(d 값을 1 증가시킴)
. 포인터 조절
라. 버킷 오버플로우 예
※ 버킷 오버플로우 예 (d≥(p+1))
- 버킷 4가 만원인 상태에서 모조키가 10으로 시작하는 레코드 삽입
- 버킷을 분할 : 빈 버킷 할당
ㆍ 모조키 11로 시작되는 레코드를 새 버킷으로 이동
- 디렉터리의 110과 111의 포인터 값은 새 버킷을 지시하도록 변경
- 분할된 버킷의 깊이는 2로 증가
마. 삭제
- 삭제할 레코드를 찾아 삭제
- 한 버킷에 하나만 있는 레코드를 삭제하는 경우
. 버디 버킷을 검사, 두 버디에 있는 레코드들이 한 버킷에 들어갈 수 있으면 합병
* 버디 버킷(buddy bucket) : 똑같은 깊이 값(p)을 가지고 있고 그 모조 키들의 처음 (p-1)비트들은 모두 같은 버킷
. 버킷의 새로운 깊이 값은 p-1
. 모든 버킷들의 깊이 값이 디렉터리 깊이 값보다 작게 되면 디렉터리의 깊이를 하나 감소(d ← d-1)
* 디렉터리 크기는 반으로 줄어듦
* 포인터 엔트리들을 적절히 재조정
바. 확장 해싱의 장단점
|
구 분 |
주요 내용 |
|
장점 |
파일의 크기가 크더라도 레코드를 접근하기 위해 디스크 접근이 두 번을 넘기지 않음
버켓 주소 테이블의 크기가 작으므로 저장 공간이 절약됨 |
|
단점 |
버켓 주소 테이블을 생성해야 하는 부담이 있음 각각의 버켓 주소가 실제의 버켓을 포인트하고 있으므로데이터의 숫자가 적으면 오히려 디스크의 낭비일 수 있음 버켓을 버켓 주소를 통해 간접적으로 검색하므로 추가적인 검색이 필요함 |
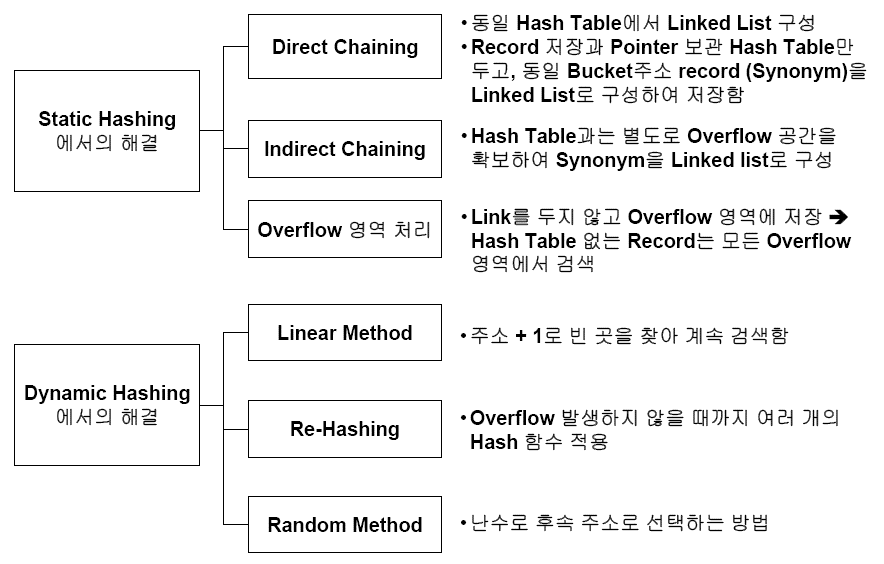
5.충돌 해결 전략 및 해결 방안
가. Collision 해결 전략
|
방 법 |
주요 내용 |
|
Bucket 해싱 |
테이블 엔트리에 몇 개의 키 값이 들어가도록 공간을 만들어 놓음충돌시 동일 버켓에 쌍아 놓음 버켓의 오버플로우 발생 가능증가로 인한 성능저하메모리 낭비 |
|
Open Addressing |
충돌이 발생할 경우 다음 가용 공간에 저장 영역을 찾을 때까지 계속 수행하는 단순한 방법 별도 포인터나 데이터 스트럭처 사용하지 않음 |
|
Closed Addressign |
같은 해시값을 가지는 레코드들을 리스트로 만들어 관리 충돌을 쉽게 다룰 수 있음 linked list를 통해 second clustering이라는 데이터 치우침 현상 방지 데이터 영역이 동적으로 할당되므로 테이블의 크기에 관계없이 다량의 레코드 관리가 가능함 |
나. Collision 해결방안
6. 해싱의 장단점 종합
|
구 분 |
주요 내용 |
|
장점 |
보다 상당히 빠른 검색속도를 지님 데이터에 대한 입력이나 삭제가 용이 검색시간이 데이터의 양과 무관하게 일정하게 유지 |
|
단점 |
연속적인 데이터 검색에는 비효율적 디스크 공간이 비효율적으로 사용됨 디스크 공간을 늘리고 재구조화하게 되면 재 검색을 위한 상당시간 소요됨 |
Reference
1. 보안 분야의 해싱
가. 개념
데이터의 무결성 및 메시지 인증에 사용하여 정보보호의 여러 메커니즘에 이용
고정되지 않은 임의의 길의의 비트열을 입력으로 하여 고정된 해쉬 코드 생성하여 암호학적으로 풀 수 없는 키를 만들어 내는 것
나. 사용 용도
|
용 도 |
내 용 |
|
전자서명 |
메시지 전송시 송신자가 전자서명을 하여 위변조 막음 |
|
부인방지 |
메시지 수신자가 수신한 메시지를 부인하거나 이의를 제기할 경우를 방지하기 위한 서비스 |
다. 해쉬 함수의 기본 요건
입력은 어떤 크기라도 무관하도록 가변적인 길이를 수용해야 하며 출력은 고정된 길이를 가져야 함
H(x) 즉 해쉬함수 H의 입력인 x는 어떠한 값이 들어와도 계산하기 쉬워야 하며, H(x)는 일방향성(역변환 불가)이어야 하고, 충돌이 없어야 함
라. 대표적인 해쉬 함수
|
구 분 |
내 용 |
|
SNEFRU |
1990. R.C. Merkle 32bit 프로세서 구현을 용이하게 할 목적으로 생성 를 입력하여 125 또는 256 bit의 코드 생성 년 차분 공격법에 의해 해독됨 |
|
N-NASH |
1989 일본 미야자키 128bit à 128bit out 년 차분 공격법에 의해 해독 |
|
MD4 |
1990 Rou Rivest |
|
MD5 |
|
|
SHA |
Secure Hash Algorithm
에 기반을 둔 160Bit 해쉬 코드 출력 MD5 보다 32bit 긴 해쉬코드를 출력하여 속도는 25% 느림 |
2. 자료 구조 분야의 해싱
가. 해싱의 개념
기억 장소에 저장하는 레코드를 검색이 빠르도록 내용을 해싱함수를 이용하여 주소를 지정하는 방식을 말함
컴파일러의 심볼 테이블 사용
나. 해싱의 필요성 및 장점
순차파일에서는 테이터를 액세스 할 경우 인덱스를 이용하거나 트리 구조를 이용한 이진 검색이 필요함으로 입출력 연산이 많아져 처리 속도에 지장
정보를 검색할 때 키 비교 없이 계산에 의해 직접 검색하므로 속도가 빠르고, 삽입 및 삭제가 빈번한 자료 처리에 적합함
충돌이 많이 발생하면 Overflow 처리가 많아져서 기억 장소의 낭비가 심화됨