SQL Full table scan
태그 :
1. 데이터 블록 엑세스 방식인 Index Scan과 FULL Table Scan의 개요
가. Index Scan(DB file sequential read) 개념
1) 인덱스를 경유하여 데이터 블록을 엑세스하는 방식
2) 즉, 조건을 만족하는 인덱스의 ROWID 정보를 이용하여 실제 테이블 데이터 블록(Block)의 로우를 일일이 랜덤하게 엑세스함
나. FULL Table Scan(DB file Scattered read) 개념
1) 전체 테이블을 첫번째 블록부터 차례대로 스캔하여 조건을 만족하는 데이터 블록을 엑세스하는 방식
2. Index Scan과 FULL Table Scan의 수행 방식
|
FULL Table Scan |
Index Scan |
|
|
|
|
1.테이블의 첫번째 블록부터 차례대로 엑세스 됨 2.테이블의 전체 블록이 모두 엑세스 될 때까지 계속 수행 |
1. B* Tree 방식으로 조건을 만족하는 첫번째 인덱스 로우를 액세스 2.인덱스 로우에 있는 ROWID정보를 이용하여 대응되는 테이블의 로우를 액세스 3. 다음 인덱스 로우를 차례로 스캔하여 대응되는 테이블의 로우를 찾는 작업을 인덱스 로우가 끝날 때 까지 수행 |
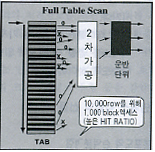
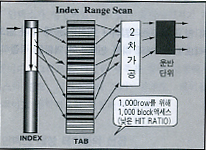
2. Scan Cost 비교 및 손익분기점
가. Scan Cost 계산
1)가정: 테이블 row 10,000개, 1 block = 10개 row, 인덱스 컬럼의 분포도: 10%, 인덱스 로우에 대응하는 테이블의 로우는 각 블럭에 하나씩만 존재(최악의 경우를 가정)
|
FULL Table Scan |
Index Scan |
|
총 액세스 블록 수 테이블의 총 row 수 / 블록내의 row 수 = 10,000/10= 1000개 |
1. 총 인덱스 수 테이블의 총 row 수 * 인덱스 컬럼 분포도 = 10,000 * 10% = 1000개 2.인덱스에 대응하는 테이블의 로우가 각 블록에 하나이므로 1000개의 블록 액세스 필요 |
|
두 경우 모두 1000개의 블록 액세스가 필요함 즉, 인덱스로 1/10을 액세스한 경우와 전체 테이블을 모두 액세스한 경우 비용이 동일 하여 인덱스 사용의 손익분기점은 10%임 |
|
나. 분포도와 손익분기점

1) 컬럼의 분포도가 10~15% 이상인 경우는 인덱스의 ROWID 를 통한 RANDOM ACCESS 비용 때문에 TABLE FULL SCAN 이 더 좋음
[참고] 분포도 : 어떤 컬럼이 테이블에 평균적으로 분포되어 있는 정도. 즉, 분포도 = (테이타별 평균 로우수 / 테이블의 총 로우수) x 100 = (1 / 컬럼값의 종류) x 100
2) 예, 5개 사업장을 가진 회사의 ‘사업장’ 컬럼은 값의 종류가 5가지 이므로 (1/5)*100=20% 임
4. 데이터 블록 엑세스 방식에 따른 SQL Select 연산의 비용 계산
가. SQL Select 연산의 비용계산
1) 조건: Table의 레코드 수= r, 한 개의 블록에 저장되는 레코드 수= bfr, 전체 블록 개수 = r/bfr = b, Selection Cardinality = 선택률 * 테이블의 레코드 수
2) Selection Cardinality : 동등조건을 만족하는 레코드들의 평균 개수
3) 선택률 s: 전체 레코드 수에서 조건을 만족하는 레코드 수의 비율(=컬럼 분포도)
|
엑세스 방식 |
Select 연산의 비용(디스크 연산 비용) |
|
|
동등조건(=) |
범위조건(>,<) |
|
|
Full Table Scan(선형 탐색) |
-평균 : b/2개 -최악: b개 (조건을 만족하는 레코드가 없는 경우 |
b개 |
|
기본 인덱스 스캔 |
인덱스 단계수 + 1 |
인덱스 단계수 + b/2 (기본 인덱스 접근 후 그 레코드 다음에 위치한 모든 레코드 검색) |
|
클러스터링 인덱스 스캔 |
인덱스 단계수 + (s*r)/bfr |
인덱스 단계수 + b/2
|
|
보조 인덱스(B+ 트리) 스캔 |
인덱스 단계수 + (s*r) (인덱스가 검색한 레코드들이 모두 서로 다른 블록에 위치 할 경우) |
인덱스 단계수 + 첫번째 단계의 인덱스 블록수/2 + r/2 |
나. SQL Select 연산의 비용 계산의 예
-조건: EMPLOEE 테이블의 레코드 수 = 10,000, 한 블록에 저장되는 레코드 수 = 5, 기본키 = SSN, 기본키이므로 Selection Cardinality(S) =1, 인덱스 단계수(B+ 트리 높이)=4
-SQL : Select * from EMPLOYEE where SSN=’12345’;
-Full Table Scan 비용(블록 엑세스 개수)
: 최악 b = 10,000/5 = 200개, 평균 b/s = 200/2 = 100개
-보조 인덱스(B+ 트리) 스캔 비용(블록 엑세스 개수)
: 인덱스 단계수 + (s*r) = 4+1(기본키) = 5개
-컬럼 분포도가 낮은 경우(기본키이므로 동일한 값이 하나 존재) 인덱스 스캔이 효과적임
-데이터 블록 엑세스 방식 비교
|
구분 |
Full table scan |
Index Scan |
Fast full index sacn |
|
특징 |
1)순차적 블록 엑세스 2)멀티 블록 I/O 및 별렬화 가능 |
1)인덱스 블록 엑세스 후 ROWID 를 통해 데이터 블록 획득 2)비 순차적인 블록 엑세스 |
1)질의에 필요한 모든 컬럼이 인덱스에 포함된 경우 2)멀티 블록 .I/O 및 별렬화 가능 |
|
방식 |
|
|
|
|
사용범위 |
-저용량 데이터 조회 -한 행의 15% 이상을 검색하는 경우 |
- 데용량 데이터의 조회 - 한행의 15% 이하의 검색을 하는 경우 |
|

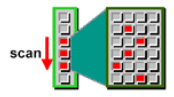
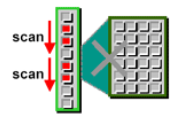
5. Full Table Scan과 Index Scan의 Cost 계산
가. 가정
|
구분 |
값 |
설명 |
|
Blocks |
100 |
블록 개수 |
|
MBRC |
4 |
db_file_multiblock_read_count |
|
sreadtim |
5 |
Single Block I/O 의 평균 수행 시간(ms) |
|
mreadtim |
10 |
Multi Block I/O 의 평균 수행 시간(ms) |
나. Full Table Scan Cost
1) 공식
Cost = Single Block I/O Count + Adjusted Multi Block I/O Count + Adjusted CPU Count
2) 계산
|
구분 |
값 |
|
Single Block I/O Count |
0 |
|
Adjusted Multi Block I/O Count |
Multi Block I/O Count * 가중치 = (Blocks / MBRC) * (mreadtim / sreadtim) = ( 100 / 4 ) * ( 10 / 5 ) = 50 |
|
Adjusted CPU Count |
<Small Value> (0.xxxx) |
|
Cost = (100/4)*(10/2) = 50 (약 50정도의 Cost가 필요) Full Table Scan의 Cost는 Table의 Block수, MBRC, Multi Block Read의 가중치에 의해 결정돤다. => MBRC를 제어함으로써 Table Full Scan Cost 제어가능 |
다. Index Scan Cost
1) 공식
Cost = Blevel + Leaf Blocks * Index Selectivity + Clustering Factor * Table Selectivity + Adjusted CPU Count
2) 계산
|
구분 |
값 |
설명 |
|
Blevel |
2 |
Root Block 에서 Leaf Block 까지 찾아가는 Cost |
|
Leaf Blocks * Index Selectivity |
4 * 1 / 4 |
조건에 맞는 Index Leaf Block 을 읽는 Cost |
|
Clustering Factor * Table Selectivity |
8 * 1 / 5 |
조건에 맞는 Table Block 을 읽는 Cost |
|
Adjusted CPU Count |
<Small Value> (0.xxxx) |
|
|
Cost = 2 + (4*1/4) + (8*1/5) |