데이터마이닝의 개요와 절차
태그 :
- 개념
- - 대용량의 데이터 안에서 체계적인 통계적 규칙 이나 패턴을 탐색하고 이를 의미 있는 정보로 변환함으로써 기업의 의사결정에 적용하는 일련의 과정 - KDD(Knowledge discovery in database
I. 효율적인 의사결정을 위한 유용한 정보의 추출, Data Mining의 개요
가. 데이터 마이닝(Data Mining)의 정의
- 대용량의 데이터 안에서 체계적인 통계적 규칙 이나 패턴을 탐색하고 이를 의미 있는 정보로 변환함으로써 기업의 의사결정에 적용하는 일련의 과정
- KDD(Knowledge discovery in database)
나. 데이터 마이닝(Data Mining)의 특징
1) 대용량의 관측 가능한 자료를 다루고 컴퓨터 중심의 기법.
2) 경험적 방법이 중시
3) 현재의 자료보다 미래의 자료를 잘 설명할 수 있는 모형을 추구.
다. Data Mining의 등장배경
1) 고도의 전문적인 의사결정 시스템의 필요성 증가
2) Datawarehouse활성화에 따라 Data Mining구축인식 확산
라. Data Mining 주요기능
|
구분 |
주요 기능 |
|
검증 |
사용자 응용시스템의 가설 입증 |
|
발견 |
관계 및 패턴 발견 |
|
예측 |
특정객체의 미래행위 예측 |
|
묘사 |
사용자가 이용 가능한 형태로 표현/변환 |
II. Data Mining 적용기법 및 연관규칙(Association Rule)측정 방법
가. Data Mining 적용기법
|
적용기법 |
설명 |
|
연관성 탐사 |
- 관련성이 강한 데이터의 조합을 통해 패턴을 발견 하는 것 - 제품간의 관계를 찾아내는 장바구니 분석에 주로 사용됨. [사례] 넥타이를 구매하는 고객이 셔츠를 50%이상 구매하고 정장과 벨트를 구매하는 고객은 코트를 구매할 확률이 40% 이상.
|
|
연속성 규칙 Sequence |
- 트랜잭션 이력 데이터를 시계열적으로 분석하여 트랜잭션의 향후 발생 가능성을 예측하는 것 [사례] A 품목을 구입한 회원이 향후 H 품목을 구입할 가능성은 75% 이다.-> 5번 회원에게 H 품목 추천하여 마케팅의 정확도를 높임 |
|
분류 규칙 Classification |
- 이미 알려진 특정 그룹의 특징을 부여하고 정의된 분류에 맞게 구분 [사례] 은행 대출을 위한 고객 신용도 구분 |
|
군집 분석 Clustering |
- 상호 유사한 특성을 지닌 데이터를 그룹화하여 패턴을 분석 [사례] - A~D의 데이터를 집단화하는 과정에서 고객군집별 특성을 파악함 - A 군집은 월소득 300만원 이상, 자녀 2-3명 연령이 30대 군집 - B 군집은 대졸이상, 자녀는 모두 출가했고, 연평균 구매액이 200~300만원 정도 |
|
특성화 Characterization |
- 데이터 집합의 일반적인 특성을 분석하는 것으로 데이터의 요약 과정을 통해 특정 규칙을 발견하는 것 |
나. 연관규칙(Association Rule)측정 방법
1) 연관규칙(Association Rule)의 정의
|
연관 규칙 |
정 의 |
|
지지도( Support) |
물건을 구매한 전체 거래 내역 중에서 X 또는 Y 라는 물건을 살 확률 |
|
신뢰도(Confidence) |
X라는 물건을 산 거래 중에서 Y라는 물건을 살 확률 |
|
향상도(Lift) |
X, Y 품목간의 상관관계 |
2) 연관규칙(Association Rule)의 측정 방법
|
연관 규칙 |
측 정 방 법 |
예 |
|
지지도 Support |
P(X,Y) / 전체 트랜잭션의 수 |
빵, 우유를 구입한 트랜잭션의 수 / 전체 트랜잭션의 수 |
|
신뢰도 Confidence |
P(X,Y) / P(X) |
빵, 우유를 구입한 트랜잭션의 수 / 빵 을 구입한 트랜잭션의 수 |
|
향상도 Lift, Improvement |
P(X,Y)/ (P(X)*P(Y)) * 전체 트랜잭션의 수 |
빵, 우유를 구입한 트랜잭션의 수/ ((빵을 구입한 트랜잭션의 수)*(우유를 구입한 트랜잭션의 수)) * 전체 트랜잭션의 수 |
- Lift =1 : 서로 독립적, Lift <1 : 음의 연관성, Lift >1: 양의 연관성
3) 연관규칙(Association Rule) 적용 사례
|
거래번호 |
품목 |
|
1 |
우유, 빵, 버터 |
|
2 |
우유,버터, 콜라 |
|
3 |
빵, 버터, 콜라 |
|
4 |
우유,콜라, 라면 |
|
5 |
빵, 버터, 라면 |

- 리프트가 1보다 크므로 양의 상관관계 즉, 상호 동시판매 영향도가 큼을 알 수 있음
III. Data Mining의 구축 절차
|
단계 |
설명 |
|
Data 선택 |
- 필요 Data의 위치, 형태, 완전성 등을 파악하여 |
|
Data 정제 |
- 확보된 데이터의 완성도를 높이는 작업 |
|
Data 보완 |
- 데이터의 양과 깊이를 늘리는 작업 |
|
Data 변환 |
- 불필요한 레코드, 항목삭제, 파생 항목을 만들거나 항목의 값을 세분화 또는 그룹핑하는 작업 |
|
Data Mining 적용 및 평가 |
- 구축된 Data 에 대한 Data Mining 적용기술을 적용하여 도출된 결과를 해석 - 의미있는 결과는 의사결정에 적용 |
IV. Data Mining과 관련기술 OLAP과의 비교
가. Data Mining과 OLAP의 개념도

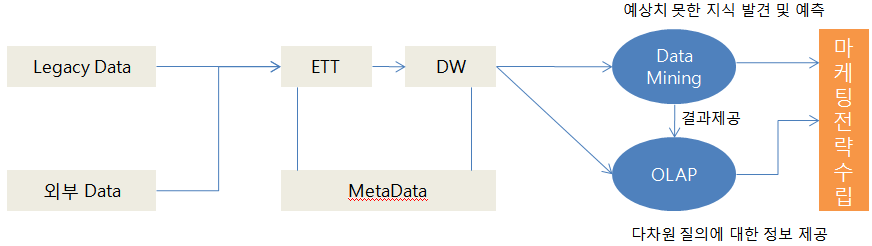
- OLAP(Online Analytical Processing)은 정보사용자가 직접 접근하여 다차원 질의를 통해 대화식으로 정보를 탐색하고 분석하는 프로세스
나. Data Mining과 OLAP의 비교
|
구 분 |
Data Mining |
OLAP |
|
개 념 |
컴퓨터에 의해 가설을 세우고 검증하는 기법 |
분석과정에서 사용자들의 사전 지식 검증 |
|
주체 |
컴퓨터 |
사용자 |
|
단점 |
분석기법에 대한 이해 필요 |
모든 질문을 사용자가 생각 |
|
특 징 |
진보적인 방법 |
고정적인 방법 |
|
통 합 |
주로 상호 보완적으로 사용되며 일반적으로 마이닝을 하기전에 OLAP을 미리 적용 |
|
다. Data Mining과 OLAP의 통합 방안
- OLAP벤더들이 툴 기능에 Data Mining 기법추가
- OLAP이 DBMS엔진과 통합됨에 따라 Data Mining을 위한 데이터 준비 시간 단축, 사용자의 접근 용이
- OLAP의 검증형 접근법과 DataMining의 발견형 접근법의 통합은 사용자의 의사결정을 효과적으로 지원
V. Data Mining의 도구 선정 시 고려사항
가. 사용자 편리성 : 사용하기 쉽고 통계자료 등의 사용이 용이해야 함
나. DB접근 개방성 : 다양한 Source Data에 독립적으로 접근이 용이해야하며 EAI, BI 등과의 통합 연동 서비스 제공
다. 운영 환경 : 다양한 플랫폼에서 적용 가능
라. 다양한 Data Mining 알고리즘 제공 : 데이터 추출을 위한 반복 적용 및 측정에 용이 해야 하며, 기본적인 추출 알고리즘 제공
Ⅵ. 데이터 마이닝(Data Mining) 활용분야 및 전망
가. Data Mining의 활용분야
1) 유통분야: 매출,수익성분석, 광고효과분석, 고객패턴분석
2) 통신분야: 고객성향 변동관리(이용시간, 지역)
3) 금융분야: 고객구매 패턴 및 시기, 신용도 분석
4) 치안분야: 범인의 행동패턴, 심리분석
5) 의료분야: 과거자료로 판별 및 분류분석
나. Data Mining 의 전망
- Data Mining을 위한 통합된 환경을 제공하고 다양한 업무에 지속적으로 적용 가능한지 고려하여 Tool을 선택
- 경험과 지식을 갖춘 Data Mining 전문가와 이를 활용할 수 있는 조직 프로세스 정립 필수웹을 통한 채널의 증대로 Web Mining을 적용하는 기술의 연계