데이터마이닝-연관규칙(Association)
태그 :
- 개념
- - 대용량의 데이터에 숨겨져 있는 데이터간의 관계, 패턴을 탐색하고 이를 모형화하여 업무에 적용할 수 있는 의미 있는 정보로 변환함 으로써 기업의 의사결정에 적용하는 일련의 과정
I. 효율적 의사결정을 위한 의미있는 지식 추론, Data Mining의 개요
가. 데이터 마이닝(Data Mining)의 정의
- 대용량의 데이터에 숨겨져 있는 데이터간의 관계, 패턴을 탐색하고 이를 모형화하여 업무에 적용할 수 있는 의미 있는 정보로 변환함 으로써 기업의 의사결정에 적용하는 일련의 과정
나. 데이터 마이닝(Data Mining)의 특징
- 정보의 Activity와 Rule을 추론하여 경영의 경쟁력 강화를 위하여 목표 예상을 가능하게 함
- 지식집약적(Knowledge Intensive) : 응용분야 지식, DB/DW지식, 데이터마이닝 기법에 대한 지식
다. 데이터마이닝 DW 관계
- DW는 정제된, 표준화된, 일관된 데이터를 만들어 데이터 마이닝 적용이 용이하게 함
- DW는 효율적인 데이터 마이닝의 출발점
II. Data Mining의 과정
가. 데이터 마이닝(Data Mining)의 수행단계

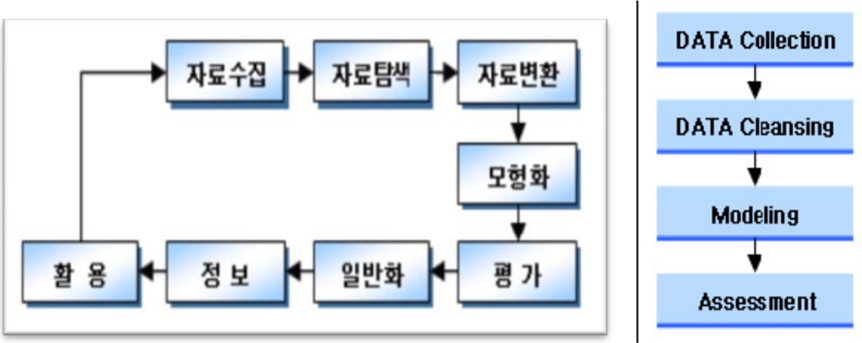
나. 데이터 마이닝(Data Mining)의 각 단계별 수행내용
|
구분 |
수행 내용 |
|
Data 선택 |
|
|
Data 정제 |
|
|
Data 보완 |
|
|
Data 변환 |
|
|
Data Mining적용 및 평가 |
|
III. 데이터 마이닝의 연관 기법 (Association Rule
가. 데이터 마이닝의 연관기법의 개념
- 특정 트랜잭션에 하나의 제품이 존재하고 동시에 같은 트랜잭션에 다른 제품이 존재할 때 이러한 두 제품 사이의 연관성을 발견하는 기법
- 대용량 데이타베이스 내의 단위 트랜잭션에서 빈번하게 발생하는 사건의 유형을 발견하는 기법
- 동시에 구매될 가능성이 큰 상품들을 찾아냄으로써 시장바구니 분석(Market Basket Analysis)에서 다루는 문제들에 적용 가능

- 연관규칙: “상품 A가 구매되어진 경우는 상품 B도 구매된다.”
나. 데이터 마이닝 연관기법의 과정
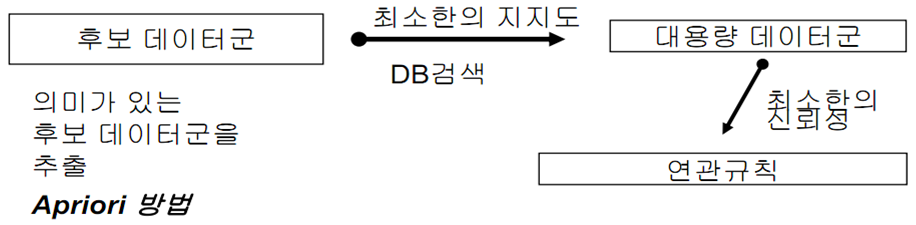

- 대용량 데이터군 검색: 트랜잭션을 대상으로 최소지지도 이상을 만족하는 빈발항목 집합을 발견하는 과정
- 연관규칙을 발견: 발견된 다량 항목 집합 내에 포함된 항목들 중에서 최소신뢰도 이상을 만족하는 항목들 간의 연관규칙을 생성하는 단계
- Apriori 알고리즘 : 96회 기출풀이 참조
IV. 연관 정도를 정량화 하기 위해서 세 가지 기준
|
구분 |
설명 |
|
지지도(Support) |
|
|
|
|
|
신뢰도(Confidence) |
|
|
|
|
|
리프트 (Lift / Improvement) |
|
|
|





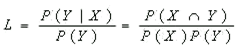


V. 연관규칙의 장단점
|
구분 |
설명 |
|
장점 |
|
|
단점 |
|