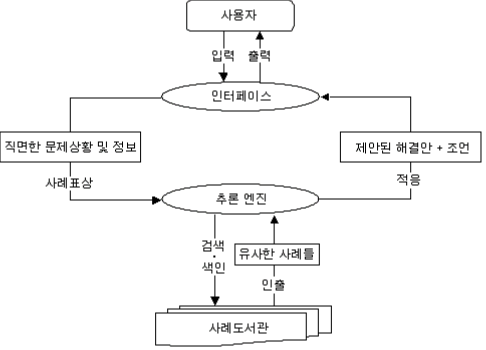
기억기반추론(MBR)
태그 :
- 개념
- 기억기반추론(MBR : Memory-based reasoning)의 정의 - 과거에 현재의 문제와 유사한 문제가 존재하였고 그것이 어떻게 해결되었는지를 안다면, 과거의 경험을 바탕으로 현재 문제의 해결책을 추론 할 수 있다는 이론
I. 경험기반 마이닝 기법, 기억기반추론의 개요
가. 기억기반추론(MBR : Memory-based reasoning)의 정의
- 과거에 현재의 문제와 유사한 문제가 존재하였고 그것이 어떻게 해결되었는지를 안다면, 과거의 경험을 바탕으로 현재 문제의 해결책을 추론 할 수 있다는 이론

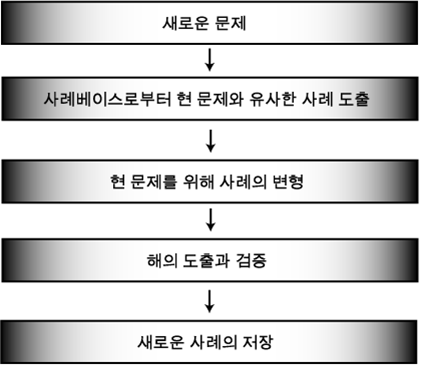
- Case Based Reasoning = Examplar-based reasoning = Instance-based reasoning = Analogy-based reasoning 등 다양한 용어로 사용
나. 기억기반추론(MBR)의 특징
- 데이터마이닝 기법 중 하나이며, 분류 및 예측 문제 모두에 효과적으로 적용 가능한 기계학습기법
- 다른 마이닝 기법과 달리 데이터 자체를 이용하므로 레코드의 포맷에는 개의치 않음.
- 두 레코드간의 거리를 나타내는 distance function과 답에 도달하기까지의 결과를 조합한 combination function을 계산함.
- 지리적 위치, 이미지, 복잡한 문자열등과 같이 일반적으로 다른 분석기법으로 다루기 힘든 데이터 형태를 다룰 수 있음.
II. 기억기반추론 구성요소와 프로세스
가. 기억기반추론 구성요소
- 새로운 문제 해결을 위해 사례 베이스로부터 유사 사례를 도출하고, 현 문제를 해결하기 위해 사례를 변경하고, 해를 도출하고 검증한 후, 새로운 사례를 저장하는 원리
|
구 성 |
설 명 |
|
검색(Retrieval) |
사례 검색은 새롭게 입력된 질의 사례와 유사한 최적의 과거 사례를 찾는 과정이다. |
|
재사용(Reuse) |
재사용은 검색된 사례의 해를 그대로 복사해 사용하는 방법과 검색된 사례에서 해를 유도하는 방법을 사용하여 해를 도출하는 방법으로 구성된다. |
|
수정(Revise) |
재사용 단계에서 도출된 해가 적합하지 않을 때, 새롭게 학습할 기회가 발생하게 되는데, 이 과정을 수정이라고 한다. |
|
유지(Retain) |
유지는 질의 사례에 대해 제안된 해를 지식으로 유지하기 위해 유용한 것들을 합치는 과정이다 |
나. 기억기반추론 프로세스

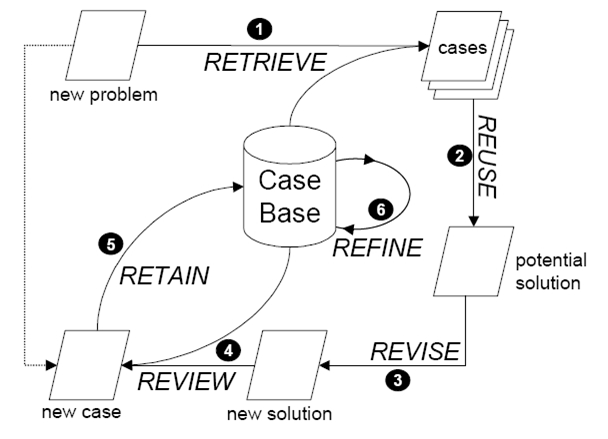
1) Retrieve 문제를 표현하기 위해 유사한 사례를 검색한다
2) Reuse 유사한 사례에 의해 제안된 솔루션을 재사용한다
3) Revise 새로운 문제에 맞게 기존의 솔루션을 교정한다
4) Review 새로운 사례로서 보존할 가치가 있는지를 비교한다
5) Retain 새로운 사례를 저장한다
6) Refine 필요에 따라 사례기반 인덱스 와 가중치를 조정한다
다. 은행대출과정과 CBR cycle의 비교
|
Mental process |
Four REs |
|
과거 대출을 조사하고 유사도 평가
가장 유사한 대출로부터 해결책 추론
최근의 환경 변화에 대한 조정과 승인
대출을 해준 경우 미래의 사용을 위해 결과를 관찰하고 기록 |
가장 유사한 경우를 Retrieve
문제를 풀기 위하여 case를 Reuse
필요하다면 제안된 해결책을 Revise
새로운 해결책을 REtain |
III. 사례기반추론(CBR)의 문제해결 적용의 예
가. 적절한 과거데이터의 선택(Case의 선택)
- 문제를 설명하는 몇 가지의 특색(features)과 그 문제를 해결하는 해결방법 혹은 결과를 포함(기호, 숫자, 계획, 멀티미디어, 텍스트 등의 형태)
- 은행의 경우 Case는 대출을 신청한 고객의 나이, 주소, 전화번호, 연간수입, 과거 거래실적 혹은 신용도, 직업, 부동산 혹은 금융자산 보유정도, 연령, 에 따른 대출과 대출거절, 성공적인 상환과 그렇지 못한 경우는 특색에 해당
- 대출과 대출거절, 성공적인 상환과 그렇지 못한 것들은 해결(Solution) 에 해당.
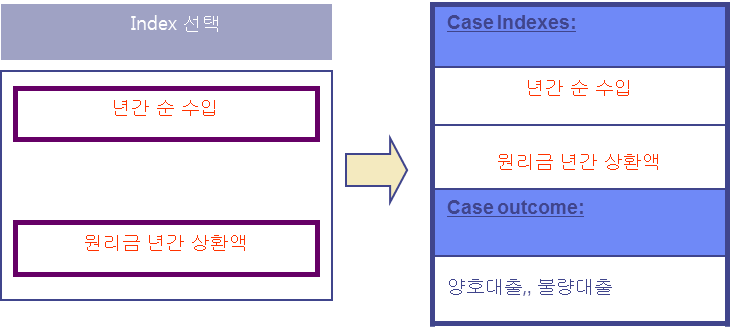
나. 인덱싱
1) 원하는 자료의 위치를 각 레코드 중 특정 항목의 내용에 의해 쉽게 찾을 수 있도록 하는 방법으로 CBR시스템에서 data의 검색 속도를 높이기 위해 사용 함. Case에서는 2가지 유형의 정보를 사용.
- 색인정보(Indexed Information): 검색을 위해 사용하는 정보
- 비색인정보(Unidexed Information): 검색을 위해 직접 사용하지는 않지만 사용자에게 상황정보를 제공

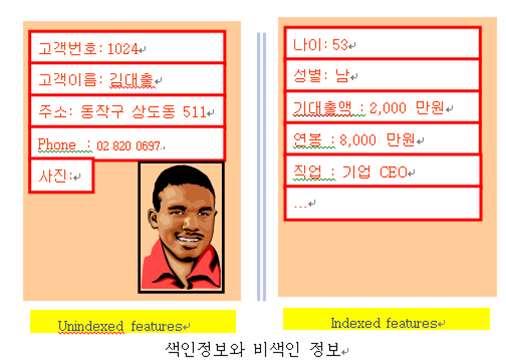
2) 색인정보(Indexed feature)는 다음의 조건을 만족하여야 함
- 예측적(Predictive)이어야 한다.
- Case-base의 목적에 부합되어야 한다.
- 미래에 다른 목적으로 사용 가능하여야 한다.
- 쉽게 인식 될 수 있어야 한다.
다. k-NN(Nearest-Neighbor) 검색
- 현재의 문제와 유사한 과거사례를 찾기 위하여 일반적으로 C4.5 index trees 알고리즘과 k-NN(Nearest-Neighbor) 방법을 이용
[index의 선택과 Case]
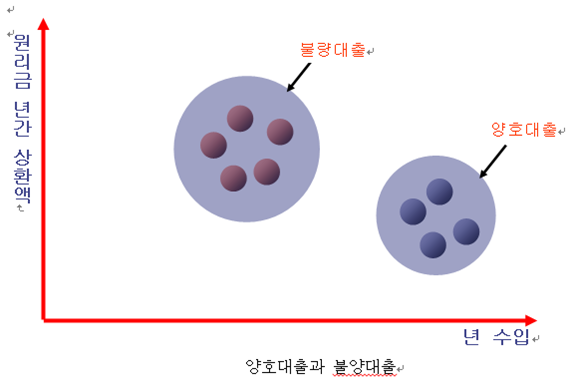
 - 상단의 그래프에서는 상대적으로 낮은 년 수입과 높은 상환금을 지불해야 하는 사람이 높은 년 수입과 낮은 상환금액을 지불해야 하는 사람에 비해 채무를 불이행할 가능성이 높음을 보여주고 있다.
- 상단의 그래프에서는 상대적으로 낮은 년 수입과 높은 상환금을 지불해야 하는 사람이 높은 년 수입과 낮은 상환금액을 지불해야 하는 사람에 비해 채무를 불이행할 가능성이 높음을 보여주고 있다.
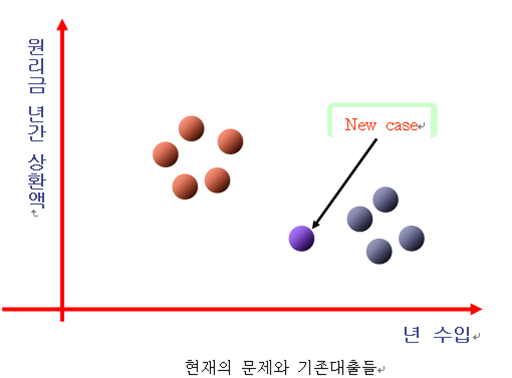
- 현재의 대출 신청인 새로운 Case가 양호대출 혹은 불량대출 중 어떤 대출에 더 유사한가를 평가 할 수 있을 것이다. 새로운 Case가 양호대출에 가까우면 대출을 승인하고 불량대출에 더 가까우면 대출을 거절 하는 의사결정을 할 수 있다. 상단의 그림은 5-NN으로 새로운 Case에서 거리(Distance)가 가장 가까운 5개의 기존 대출을 조사하여 다수의 결의 원칙에 의하여 양호대출에 더 유사하다고 판단 할 수 있다.

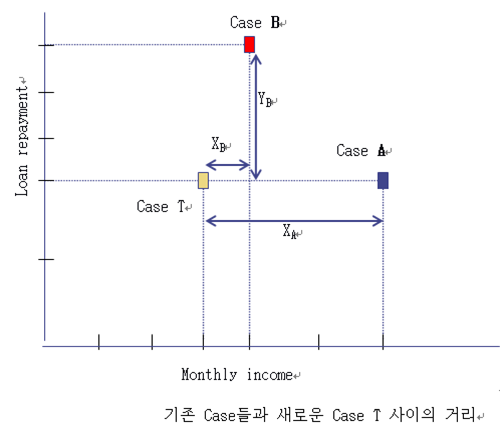
The distance of T from A: dA = XA + YA = 3+0 = 3
The distance of T from B: dB = XB + YB = 3+1 = 4
따라서 새로운 Case T는 Case A에 더 가깝고 유사하다.

T : target case,
S : source case (new problem)
n : 각 case에서 속성의 개수
i = 1… n , 개별 속성
f : case T와 case S의 속성 i에 대한 유사도 함수
wi : 속성 i의 가중치
IV. 기억기반추론(MBR)의 장단점과 적용시기
가. MBR의 장단점 비교
|
장점 |
단점 |
|
- 곧바로 이해할 수 있을만한 결과를 제공한다. - 특별한 연관관계가 없는 데이터들이나, 풀기 힘든 자료 유형에까지 적용한다. - 거의 모든 분야에 효과적으로 수행된다. - 최소의 노력으로도 Training set을 유지할 수 있다. |
- 대형 장비가 필요하다. - 데이터 처리와 보관을 위해 대형의 저장시스템이 필요하다. - 정보의 선택 여부에 따라 전혀 다른 결과가 도출될 수 있다. |
나. 기억기반추론의 적용시기 및 활용
- 기억기반추론은 예측과 분류 모두에 유용한 직접적인 데이터마이닝 기법으로 다른 기법과 비교하면 데이터의 패턴이 매우 부분적일 경우 매우 잘 적용됨.
- 데이터가 복잡하면 복잡할수록 부분적인 패턴은 전체패턴을 지배하는 경향이 있는데 이러한 많은 다른 환경에서 기억기반추론은 유용하다.
- 새로운 문제 해결을 위해 과거 사례의 해결책을 재사용한다는 기법으로 고장진단, 헬프데스크, 신용평가, 전략수립 등에 활용됨. 끝.
[참고 1 : MBR 적용시의 거리함수]
거리함수를 기호로는 d(A,B)로 나타내는데 그것의 포인트는 다음의 4가지이다.
1) 두 점 사이의 거리는 항상 정의되고 거리함수는 항상 음수가 아닌 실수이다.
d(A,B) >= 0
2) 한 점 그 자신의 거리는 항상 0 이다.
d(A,A) = 0
3) A에서 B까지의 거리나 B에서 A까지의 거리는 같다.
d(A,B) = d(B,A)
4) A 에서 B까지의 거리는 A에서 C까지의 거리와 C에서 B까지의 거리를 합한 것보다 항상 크거나 같다.
d(A,B) >= d(A,C)+ d(C,B)
거리를 정의하는 방법은 여러가지가 있는데 단순히 합하는 법과 표준화하여 합하는 것 그리고 유클리디안 거리법(Euclidean distance)가 있다.
[참고 2 : CBR 프로세스] 사례도서관
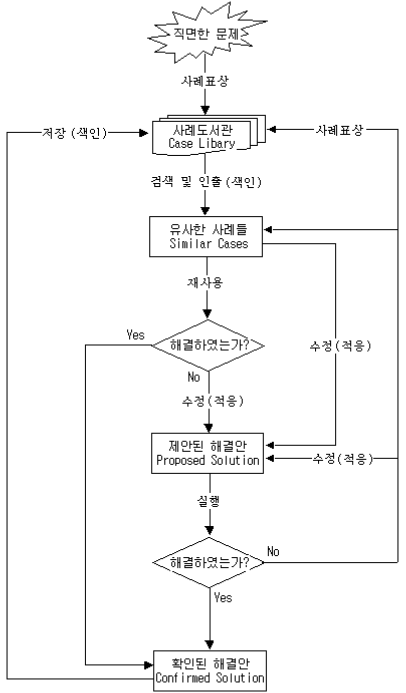
CBR 프로세스
[참고 3 : CBR 시스템모델] 사례도서관