NoSQL
태그 :
- 개념
- NoSQL(Not Only SQL) - 관계형 DB의 한계를 벗어나, Web2.0의 비정형 초고용량 데이터 처리를 위해 데이터의 읽기보다 쓰기에 중점을 둔, 수평적 확장이 가능하며 다수 서버들에 데이터 복제 및 분산 저장이 가능한 DBMS
I. 분산 DBMS환경에서의 고확장성 및 고용량 데이터 처리, NoSQL의 개요
가. NoSQL(Not Only SQL)의 정의
- 관계형 DB의 한계를 벗어나, Web2.0의 비정형 초고용량 데이터 처리를 위해 데이터의 읽기보다 쓰기에 중점을 둔, 수평적 확장이 가능하며 다수 서버들에 데이터 복제 및 분산 저장이 가능한 DBMS
나. NoSQL의 필요성
|
구분 |
설명 |
|
데이터 규모 의 확대 |
SNS와 같이 저장할 데이터가 많고 읽고/쓰기에 대해 기존 RDB가 제약적인 비즈니스 모델 등장 |
|
Web 2.0 이후 등장한 웹 기반 서비스들이 글로벌로 확장되면서 데이터의 처리양이 폭발적으로 증가함 |
|
|
웹서비스의 구조변화 |
웹 기반 서비스들의 저장할 데이터의 형태가 지속적으로 변화 |
|
사용자의 데이터 요구가 일관적이지 않고 다양해짐 |
다. NoSQL의 장/단점
|
구분 |
설명 |
|
장점 |
데이터의분산저장으로수평적인확장이용이 대용량데이터의쓰기성능의향상 Disk 기반의경우저비용으로대용량데이터저장소구축용이 |
|
단점 |
구현기술의난이도가높음. 대부분공개소스기반으로안정성보장및문제발생시기술지원이곤란함. 자체적인기술력을확보하여야구축, 유지보수가가능(Google, Yahoo, Twitter, Facebook 등대형인터넷포탈업체들이주로채택함) |
II. NoSQL 의 구성 및 특징
가. NoSQL의 구성

- NoSQL은 클러스터링을 통한 확장성을 제공하며, 기존의 SQL 방식이 아닌 OpenAPI 및 RESTFul 서비스를 활용한 쿼리를 수행한다.
나. NoSQL의 특징
|
특징 |
설명 |
|
대용량 데이터 처리 |
페타바이트 수준의 데이터 처리 수용 가능한 느슨한 데이터 구조 제공 |
|
저렴한 클러스터 구성 |
PC 수준의 상용 하드웨어를 활용 다수 서버를 통한 수평적인 확장 및 데이터 복제 및 분산 저장 가능 |
|
병목 현상 제거 |
SQL의 구조적이고 반복적인 실행 구조와 달리 Key-Value 및 Graph, Document 구조의 단순화된 형태 |
|
필요한 만큼의 무결성 |
관계형 DBMS가 논리적 구조 및 ACID의 보장에 초점을 맟춘 반면, NoSQL은 무결성 모두 DBMS에 담당시키기 보다 응용에서 일부 처리함 |
III. NoSQL의 이론적 배경, CAP Theorem의 개념
가. CAP Theorem의 정의
- 대용량 분산 데이터 저장소는 데이터 일관성(Consistency), 가용성(Availability), 단절내성(Partition Tolerance)을 모두 만족시키는 것이 불가능하므로 두 가지만 전략적으로 선택해야 한다는 이론
나. CAP Theorem의 구성과 관리 전략
|
특성 |
설명 |
|
구성도 |
|
|
Consistency |
모든 노드들은 같은 시간에 같은 데이터를 보여줘야 함. (각각의 사용자가 항상 동일한 데이터를 조회함) |
|
Availability |
몇몇 노드가 다운되어도 다른 노드들에게 영향을 주지 않아야 함. (모든 사용자가 항상 읽고 쓸 수 있음) |
|
Partition Tolerance |
일부 메시지를 손실하더라도 시스템은 정상 동작을 해야 함 (물리적 네트워크 분산 환경에서 시스템이 잘 동작함) |
|
C + A |
-시스템이 죽더라도 메시지 손실은 방지하는 강한 신뢰형 -트랜잭션이 필요한 경우 필수적 -일반 RDBMS |
|
C + P |
-모든 노드가 함께 퍼포먼스를 내야하는 성능형 - 구글의 BigTable, HyperTable, HBase |
|
A + P |
-비동기화된 스토어 작업에 필수적 - Dynamo, Apache Cassandra, CouchDB, Oracle Coherence |

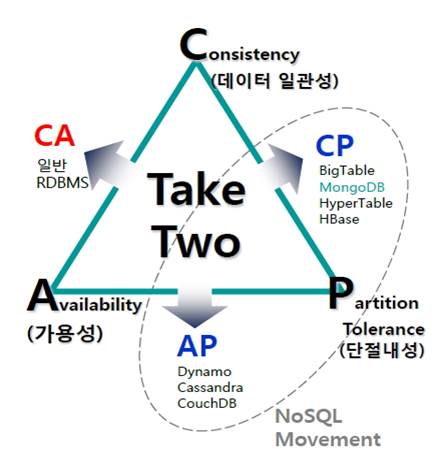
- NoSQL 시스템들은 A+P, C+P 의 특성을 가지는 분산 시스템들로 구성
- 전통적인 RDBMS의 ACID가 아닌 BASE(Basically Available, soft state, Eventually consistent) 특성을 추구
IV. NoSQL의 데이터 저장구조
가.Key/Value Store
|
구분 |
내용 |
|
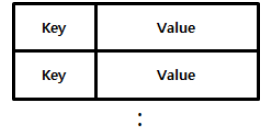
정의 |
가장 기본적인 패턴으로 대부분의 NoSQL은 다른 데이터 모델을 지원하더라도, 기본적으로 Key/Value의 개념 지원. |
|
특징 |
Key/Value Store란 Unique한 Key에 하나의 Value를 가지고 있는 형태로 Put(Key,Value), Value := get(Key) 형태의 API로 접근. |
|
상용제품 |
Oracle Coherence, Redis |
|
구조 |
|

나.Ordered Key/Value Store
|
구분 |
내용 |
|---|---|
|
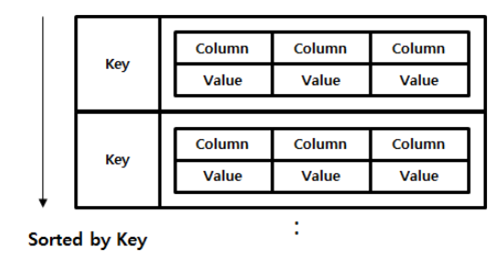
정의 |
가장 기본적인 패턴으로 대부분의 NoSQL은 다른 데이터 모델을 지원하더라도, 기본적으로 Key/Value의 개념 지원. |
|
특징 |
Key/Value Store의 확장된 형태로 Key/Value Store와 데이터 저장 방식은 동일하나, 데이터가 내부적으로 Key 순서로 Sorting되어 저장 |
|
상용제품 |
아파치(Apache)의 HBase, Cassandra |
|
구조 |
|

다.Document Key/Value Store
|
구분 |
내용 |
|---|---|
|
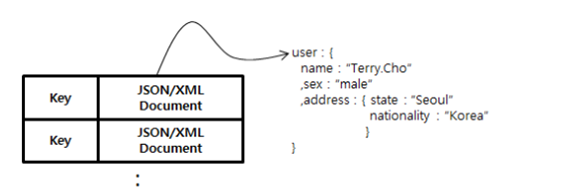
정의 |
Key/Value Store의 확장된 형태로, Key에 해당하는 Value 필드에 데이터를 저장하는 구조는 같으나, 저장되는 Value의 데이터 타입이 Document 타입 사용 |
|
특징 |
Document 타입은 MS 워드와 같은 문서를 이야기하는 것이 아니라 XML, JSON, YAML과 같이 구조화된 데이터 타입으로, 복잡한 계층 구조를 표현. |
|
상용제품 |
MongoDB, CouchDB, Riak |
|
구조 |
|

IV. NoSQL의 데이터 모델별 분류
|
데이터 모델 |
데이터 스토어 |
구현언어 |
설명 |
|
|---|---|---|---|---|
|
Key/Value Store |
키 기반의get, put, delete 기능제공 메모리 기반에서 성능을 우선하는 시스템과 빅데이터를 저장·처리할 수 있는 방식으로 구분 |
|||
|
Redis |
C |
대표적인 인메모리 기반의 Key/Value 스토어. Memcache 대비 value에 심플한 값뿐 아니라 문자열, 해시, 리스트, 세트 등 보다 복잡한 형태의 데이터의 정의와 처리가 가능 단일 데이터형과 작은 사이즈의 경우에는 Memcache가 성능이라 구현에 있어서 이점이 있으나 처리할 데이터의 구조가 복잡해질 경우 Redis가 유리 |
||
|
Riak |
Erlang, C |
아마존의 Dynamo 논문을 기반으로 구현된 Key/Value 스토어 Bashu Tech에서 개발해 커뮤니티 버전과 기업형 버전을 함께 제공 |
||
|
Voldemort |
Unknown |
아마존의 Dynamo 논문을 기반으로 Linkedin에서 개발하고 공개. 인메모리 캐싱을 스토리지 시스템과 결합해 memcache와 같은 별도의 캐싱 티어를 둘 필요가 없음 아파치 라이센스 |
||
|
DynamoDB |
Unknown |
최근 아마존이 클라우드 기반으로 DynamoDB를 베다 버전으로 공개 아마존 클라우드를 사용하고 있는 웹 서비스 업체들에서 매우 관심있게 주목하고 있음 |
||
|
Column Family Data Store |
테이블기반, 조인미지원, 컬럼기반으로 구글의 BigTable의 영향 |
|||
|
HBase |
자바 |
하둡기반에서 동작하고 다양한 하둡의 도구들과 상호 운영성이 좋고, 수십 테라바이트가 넘는 빅데이터에 적합. 아파치 라이센스 |
||
|
Cassandra |
자바 |
구글 BigTable의 데이터 모델과 Dynamo의 분산 기술을 결합해 구현. 빅데이터에 적합. 아파치 라이센스 |
||
|
Hypertable |
C++ |
HBase와 마찬가지로 구굴의 Bigtable 아키텍처 기반으로 구현 C++로 구현돼 성능이 매우 뛰어나고 HQL이라는 언어를 제공해 편의성을 높임 기업을 위한 상용 기술지원 서비스 제공 |
||
|
SimpleDB |
Unknown |
아마존에서 제공하는 클라우드 기반의 상용 데이터 스토어 |
||
|
Document Store |
JSON, XML 형태의 구조적 문서 저장, 조인 미 지원 |
|||
|
MongoDB |
C++ |
설치/개발이 매우 쉽고 매우 빠른 성능을 제공 많은 곳에서 적용.JSON과 같이 웹 서비스 영역에서 많이 활용되는 데이터를 바로 저장/접근할 수 있는 큰 강점을 갖고 있음. Pass와 같은 많은 플랫폼 클라우드 영역에서 기본적으로 지원하고 상용기술지원 가능 |
||
|
Couchbase |
Erlang |
2011년에 Document기반의 CouchDB와 메모리 캐싱 시스템(Key/Value 방식)인 Membase가 합병하면서 기업 내 다양한 요구 사항을 수용하기 위해 구현된 시스템 기술적인 측면에서 MongoDB와 많이 비교되고 기업에서 설치/관리가 편리한 웹 기반의 GUI를 제공 |
||
|
Graph Database |
그래프로 데이터를 표현하는DB 시맨틱웹과 온톨로지라는 분야에서 활용되고 발전된 특화된 데이터베이스 |
|||
|
Neo4j |
C++ 자바 |
속성을 가진 노드와 관계정보(즉, 그래프 또는 네트워크)를 저장, 처리하고 ACID 트랜잭션을 지원하는 데이터베이스. 그래프 데이터베이스는 시멘틱 웹의 RDF 정보를 저장/처리하는데 최적. SparQL이라는 질의 도구 제공. 한 대의 기계에서 수십억 노드와 관계정보를 저장/처리할 수 있으나 스케일 아웃 형태의 확장성은 없음 |
||
|
AlleqroGraph |
Lisp |
Alleqro Common Lisp로 유형한 Franz에서 개발한 그래프 DB로 보다 일반적인 목적으로 데이터베이스를 확장하고 MongoDB와의 연동 등 여러 가지 기술적인 시도 중 |
||
IV. NoSQL과 SQL의 비교 및 NoSQL 제품별 비교
가. NoSQL과 SQL의 비교
|
구 분 |
SQL |
NoSQL |
|
저장 데이터 |
기업의 제품판매 정보, 고객정보 등의 핵심 정보의 저장 |
중요하지 않으나 데이터 양이 많고 급격히 늘어나는 정보 저장 |
|
환경측면 |
일반적인 환경이나 분산 환경 등에 사용 |
클라우드 컴퓨팅 처럼 수천, 수만대 서버의 분산 환경 |
|
장점 |
무결성, 정합성, 원자성, 독립성, 일관성 |
비용적인 측면과 확장성 기준 |
|
처리방법 |
오라클 RAC 등으로 분산 처리 방법 |
페타 바이트 수준의 대량의 데이터 처리 |
|
특징 |
고정된 스키마를 가지며 조인 등을 통하여 데이터를 검색함 |
단순한 키와 값의 쌍으로만 이루어져 인덱스와 데이터가 분리되어 별도로 운영됨 |
|
사용 예 |
오라클 RAC |
구글의 Bigtable, 아마존의 Dynamo, 트위터의 Cassandra 등 |
나. NOSQL의 제품별 비교
|
제품 특성 |
CouchDB |
MongoDB |
Cassandra |
|
개발언어 |
Erlang |
C++ |
Java |
|
중요점 |
DB Consistency, ease of use
|
Retains some friendly properties of SQL.(Query, Index) |
Best of BigTable and Dynamo |
|
License |
Apache |
AGPL(Driver:Apache) |
Apache |
|
Protocol |
HTTP/REST |
Custom, binary(BSON) |
Custom, binary(Thrift) |
|
CAP |
AP |
CP |
AP |
|
Best used |
계산이 필요할 때, 종종 데이터 갱신이 필요할 때 |
동적인 질의가 필요할 때, 커다란 DB에서 좋은 수행능력이 필요할 때, CouchDB를 필요로 하지만 너무 많은 쓰기가 이루어질 때 |
읽기보다 쓰기가 많을 때, 시스템 컴포넌트가 모두 자바로 이루어져야 할 때, |
|
For example |
CRM, CMS 시스템, 마스터 복제를 통해 데이터 복제를 쉽게 가능하게 사용할 수 있는 서비스 |
SQL 처리를 이용해야 하는 서비스 |
은행 서비스, 재무 관련 서비스 |
V. NoSQL의 적용사례 및 전망
가. NoSQL 적용 사례
|
범위 |
사례 |
|
국외 |
Google Bigtable, Amazon’s Dynamo, Digg.com Cassandra, Twitter Cassandra |
|
국내 |
NHN 인증 플랫폼, Daum카페 |
나. NoSQL 의 전망
- 웹의 대용량화, 고성능화, 수평적 확장성(Horizontal Scalability: 즉 옆에 서버 한 대 더 배치해서 데이터베이스를 늘리고 싶다는 의미)을 해결하기 위해 CAP의 범주 중 CP, AP의 요구로 인한 NoSQL의 활용도의 증가 전망.
- 국내외적으로 오픈소스 진영의 프로젝트가 활발히 진행 중임