HDFS
태그 :
- 개념
- 저비용의 수백 내지 수천 노드를 가지는 클러스터를 이용하여 기가 바이트 또는 테라 바이트의 대용량 데이터 집합을 처리하는 응용 프로그램에 적합하도록 설계한 분산 파일 시스템
I. 대규모 데이터 처리를 위한, HDFS(Hadoop Distributed File System)의 개요
가. HDFS의 정의
- 저비용의 수백 내지 수천 노드를 가지는 클러스터를 이용하여 기가 바이트 또는 테라 바이트의 대용량 데이터 집합을 처리하는 응용 프로그램에 적합하도록 설계한 분산 파일 시스템
나. HDFS의 특징
|
특징 |
설명 |
|
빅 데이터 처리 |
-대용량 데이터 처리를 위한 경제성, 유연성, 확장성 제공 -많은 수의 파일을 저장할 수 있음 |
|
TCO 절감 |
Linux 및 저가형 서버 구성에도 신뢰성 있는 파일 시스템 제공(Commodity Hardware) |
|
Fault Tolerance |
디스크 I/O 장애에도 Replication 기법 등을 통해 높은 가용성 제공 |
|
효율적인 분산파일 시스템 |
- 메타데이터 활용을 통해 SAN과 같은 별도 장비 없이 구현가능(Multiple writers, arbitrary file modifications) - NAS 문제점인 연결 노드가 많아질수록 성능이 저하되는 문제점 극복(Streaming Data Access) |
II. HDFS(Hadoop Distributed File System)의 구성도와 구성요소
가. HDFS의 구성도
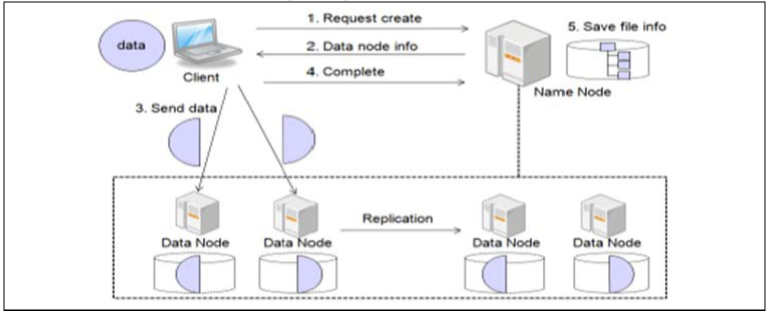
- HDFS는 마스터-슬레이브 구조로 동작하며, TCP/IP 프로토콜을 이용하여 노드 간에 통신하는 구조
- 대용량 파일 원본을 HDFS에 저장할 때 블록 단위로 나누어 저장하며, 블록크기는 64/128MB 수준임
- 노드의 실패에 대비해 데이터를 복제하여 저장하며, 동일한 랙에 위치할 경우 노드 간 대역폭이 높은 장점을 활용하는 Rack-aware 복제 배치 정책을 사용하고 있음 (내부랙 2개 노드 + 다른랙 1개 노드)
- HDFS의 구성 컴포넌트는 크게 두가지로 나뉘어 진다. (Namenodes, Datanodes)
나. HDFS의 구성요소
|
구성요소 |
설명 |
|
Name Node |
- 파일 시스템의 Metadata(디렉토리 구조, Access 권한 등)을 관리하는 서버 (일종의 Master Node) - 블록에 대한 배치정보를 관리하여, 특정 파일이 어떻게 블록으로 분할되어 어느 Data Node에 보관 유지되고 있는지를 관리 - 디렉토리 구조, 파일에 대한 각종 메타 데이타, 그리고 물리적 파일이 저장되어 있는 위치 등을 저장 |
|
Data Node |
- 실제 데이터를 저장 유지하는 서버 - 파일을 블록단위로 나누어 저장하며, 고정 사이즈 분할 단위는 디폴트 64MB, 일반적으로 128MB 사용 - Data Node간에는 데이터 복제를 통해 데이터의 신뢰성 유지함 - Namenodes와 주기적으로 통신하여 저장하고 있는 블록에 대한 정보를 Namenodes에 저장 |
|
Secondary Name Node |
- Name Node의 Metadata 로드가 실패시 Backup Node로써 사용 - Name Node에서 Secondary Name Node로 copy가 지속적으로 일어나게 됨 |
|
Job Tracker |
- 분산 환경에서 작업을 분산시키는 스케쥴 작업 (master: Task Tracker에 작업할당) |
|
Task Tracker |
- Data Node에서 Map-Reduce 역할을 수행 (slave: 할당 받은 작업을 처리함) |
- Namenodes에는 모든 블록에 대한 메타정보가 들어와 있기 때문에, Namenodes가 장애가 나면 전체 HDFS 이 장애가 나는 SFP (Single Failure Point )가 되므로, Namenodes에 대한 이중화가 필요
- Job Tracker와 Task Tracker는 각각 Name Node와 Data Node를 이용해 Map-Reduce 역할 수행
다. HDFS과 GFS와의 비교
|
항목 |
HDFS |
GFS |
|
개발주체 |
Apache(Open Project) |
|
|
구현언어 |
Java language |
Sawzall language |
|
이식성 |
이식성 높음 |
이식성 낮음 |
|
운영체제 |
저비용의 Linux 사용 선호 |
Google Operating System |
|
활용사례 |
Amazon, IBM, Yahoo 등의 클라우드 컴퓨팅 플랫폼으로 활용 |
Google의 클라우드 컴퓨팅 플랫폼에 적용 |
- HDFS는 Google의 GFS과 유사한 기능을 Java로 구현했다는 점이 가장 큰 차이점임
- 일반 x86 서버에 Disk를 붙인 형태의 저가의 서버 여러 개를 연결하여 대규모 분산 파일 시스템을 구축할 수 있게 해줌으로써, 값비싼 파일 시스템 장비 없이 분산 처리를 가능하게 해주는 것
- HDFS만을 위한 별도의 스토리지가 필요 없고 일반 Linux 장비에 탑재되어 있는 local disk를 이용해 수 천대 이상 확장 가능한 구조로 대용량 데이터를 저장 할 수 있습니다.